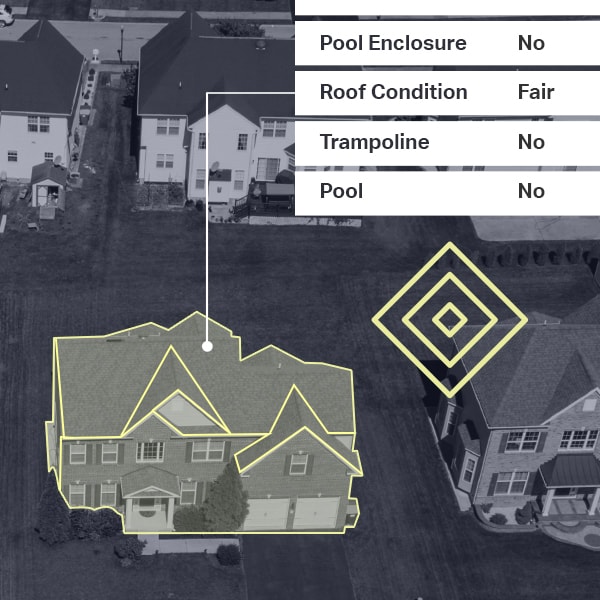
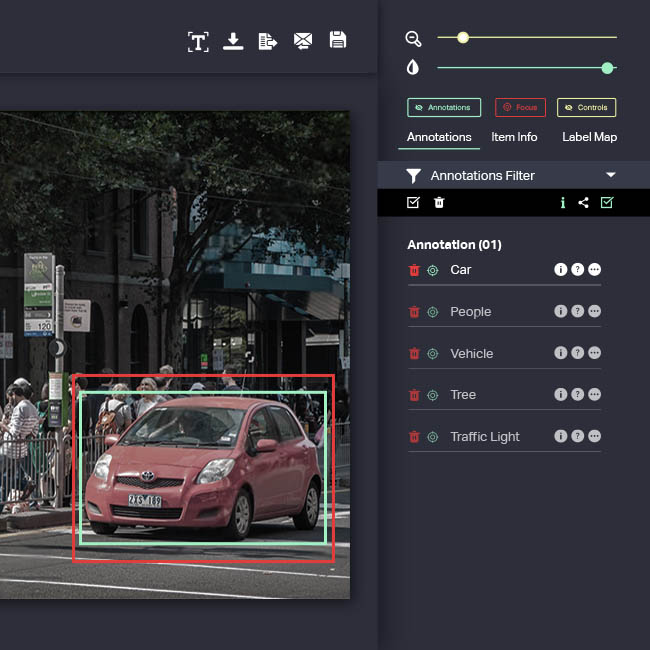
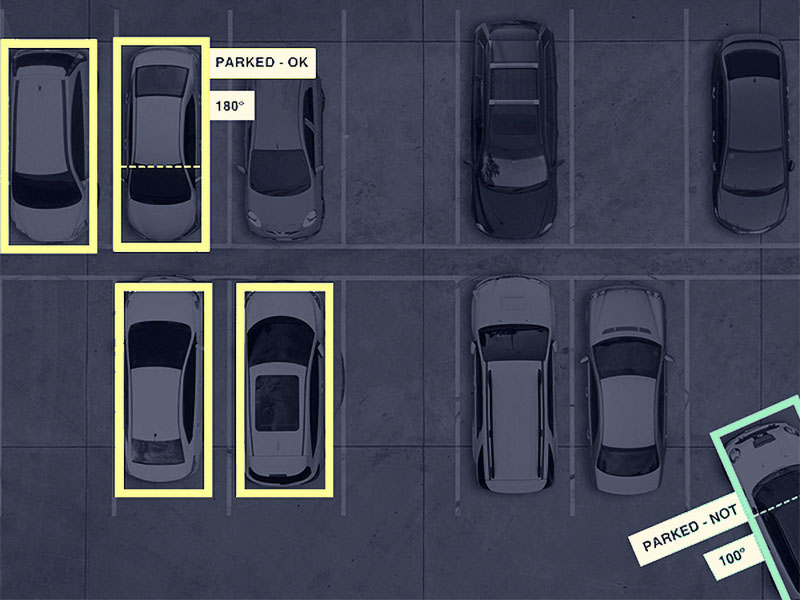
![Bounding Box annotation for detection and tracking of object, AI in Government application]()
Bounding Boxes
It is the most commonly used type of video annotation in computer vision. iMerit computer vision experts use rectangular box annotation to illustrate objects and create training data so apps and algorithms can identify and localize objects during ML processes.
![Polygon annotation where each vertex of a target object is labeled, regardless of shape, for geospatial applications]()
Polygon Annotation
Expert annotators plot points on each vertex of the target object. Polygon annotation allows all of the object’s exact edges to be annotated, regardless of shape.
![Semantic segmentation to classify each pixel of a car, use case of computer vision]()
Semantic segmentation
Videos are segmented into component parts, by the iMerit team, and then annotated. iMerit computer vision experts examine video frames and classify objects pixel by pixel.
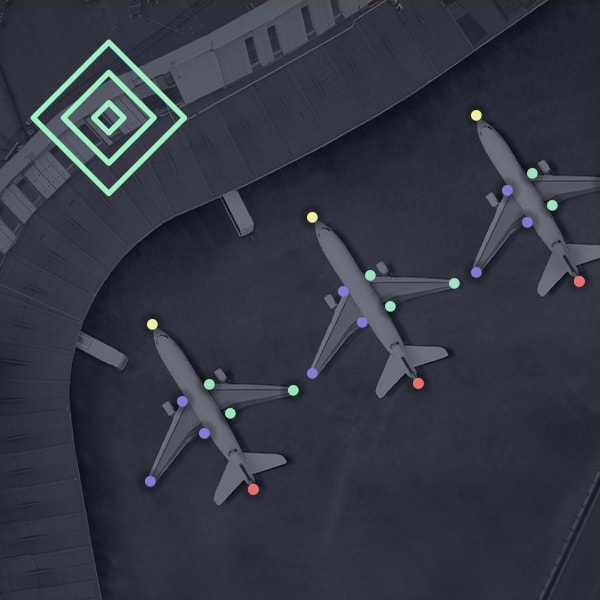
![Point annotation for locating an object its component parts in an image, for Geospatial applications]()
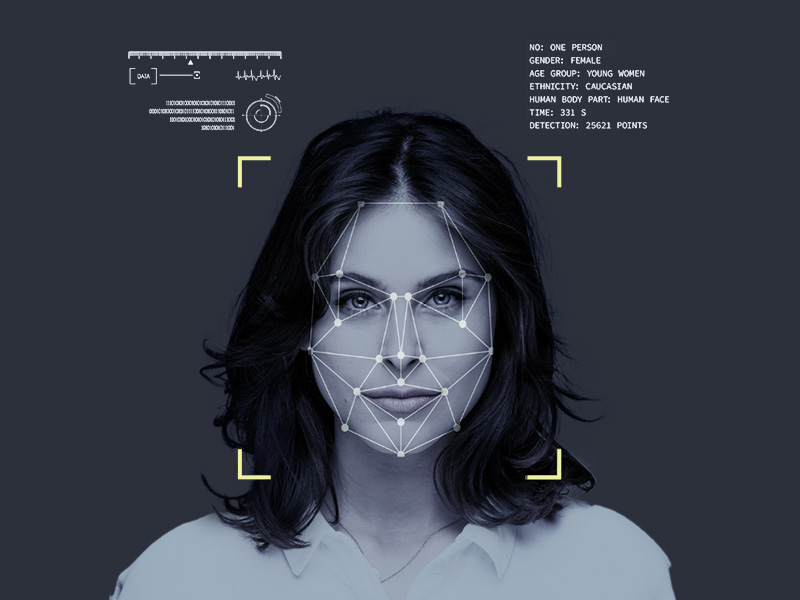
Keypoint annotation
iMerit teams outline objects and shape variations by connecting individual points across objects. This annotation type detects body features and could include facial expressions and emotions.
![Landmark annotation]()
Landmark annotation
iMerit experts use points on landmarks and peoples’ faces when annotating video footage. Expertly-conducted landmark annotation creates valuable training datasets for high-performing computer vision models.
![3d cuboid annotation]()
3d cuboid annotation
iMerit experts perform object tracking by drawing cubes around objects. This allows systems to recognize a given object’s length, width, and height.
![Polyline annotation]()
Polyline annotation
iMerit experts create training datasets using polyline annotation that teach models to identify physical boundaries to operate within.
![Rapid annotation]()
Rapid annotation
iMerit’s video annotation platform utilizes video interpolation to rapidly annotate suitable video footage. iMerit annotation experts create best-in-class video training datasets in rapid time for any AI or ML project.