Intelligent Document Processing algorithms are trained on specific data types and may produce erroneous results when presented with new or different types of documents. Data extraction from Document AI processors in certain types of data, such as legal documents or medical records, is complex and requires human expertise for accurate processing.
Doc AIAnnotations
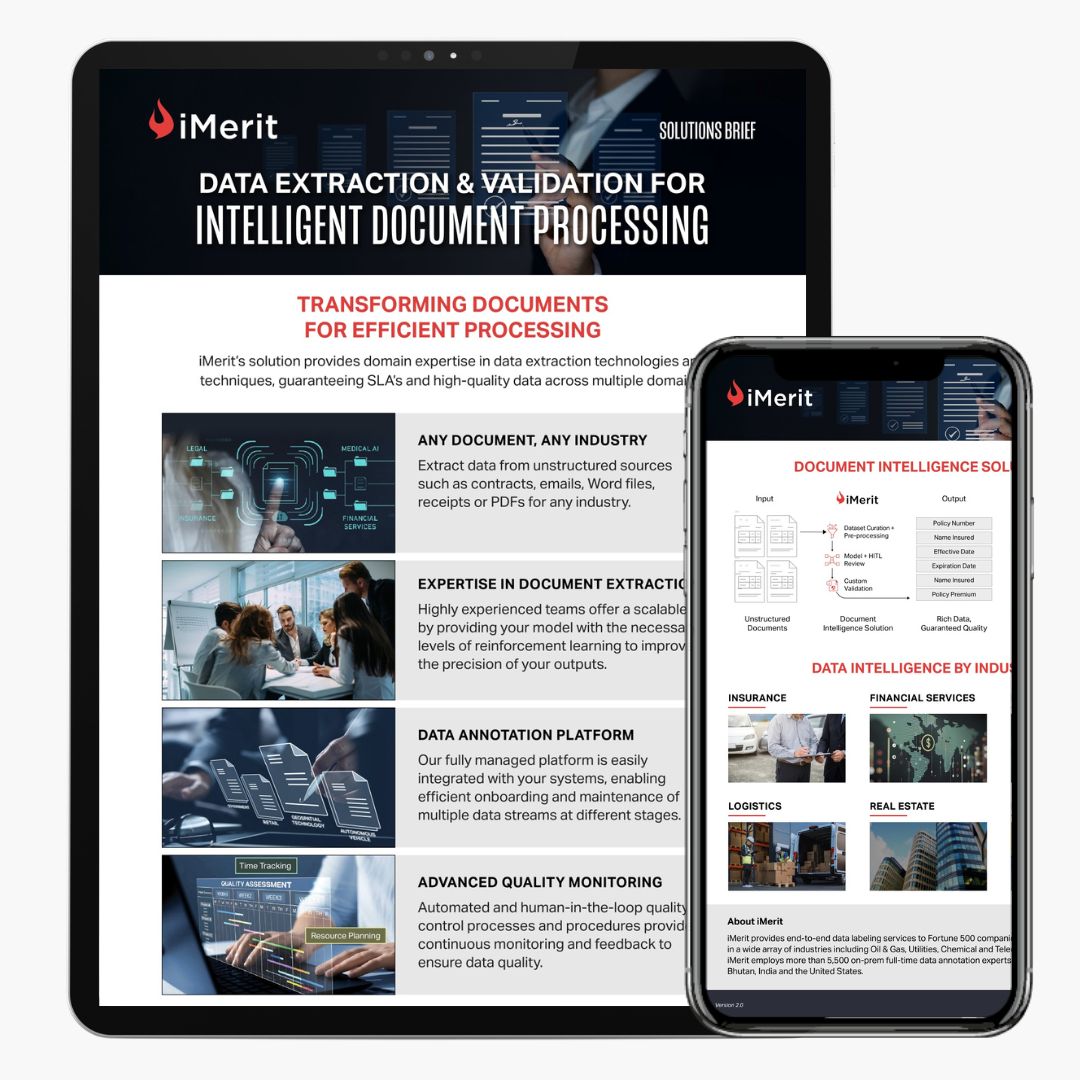
Data Extraction & Validation Services for Intelligent Document Processing Solutions with human-in-the-loop teams

Human-in-the-loop by iMerit for Data Extraction & Validation
With 10+ years of domain expertise in data extraction technologies and techniques, iMerit Human-in-the-Loop workflows for validations and corrections ensure high-quality data and guarantee SLAs across multiple domains. Domain experts and experienced annotators with 2-step quality control improve model performance for Intelligent Document Processing solutions.
We have been working with document AI companies across domains for use cases, including entity identification, pairing, localization, anonymization, classification, categorization, and summarization.
Tap into 5000+ on-premise, highly knowledgeable resources across domains including fintech, insurance, law, and healthcare to reduce time to spin up new document streams.
Resource management, including annotator allocation, task management, and performance analytics, with a goal to reduce the time per document and streamline document operations.
With human-in-the-loop, data extraction validation and edge case management will be hassle-free while ensuring that the extracted information is complete for downstream operations.
iMerit teams can plug into your annotation tool, set up an end-to-end data pipeline on our in-house fully-managed annotation platform, or work on any other 3rd party tools for your document extraction projects.
Automation-assisted and human-in-the-loop processes provide continuous monitoring and feedback to ensure data quality. iMerit data annotation platform comes with customizable built-in QC features.
Case Study

CrowdReason Saves 80% of Time in Data Extraction & Aggregation
Leading Fintech company, CrowdReason, which provides property tax software and custom data services, leverages machine learning to automate information extraction from sensitive customer documentation. However, the ML model outputs were inaccurate, resulting in many hours spent on manual data entry and corrections.
iMerit customized an end-to-end data extraction workflow that simplified the data extraction process for CrowdReason. To continually test and improve the ML algorithm accuracy, the outputs were evaluated by iMerit’s expert annotators under a consensus workflow.
"iMerit is an invaluable partner, providing us with accurate data which helped us develop our property tax software."
Brandon Van Volkenburgh, CTO & Co-founder, CrowdReason

Powering Document Intelligence Solutions
iMerit’s highly experienced teams offer a scalable solution across multiple domains to provide your document AI models with high-quality training datasets to improve output precision. Extract data from unstructured sources such as contracts, emails, word files, receipts, or PDFs with iMerit’s automated and human-in-the-loop workflows. Our fully managed platform easily integrates with your systems, enabling efficient onboarding and maintenance of multiple data streams at different stages.

Download Solution Brief