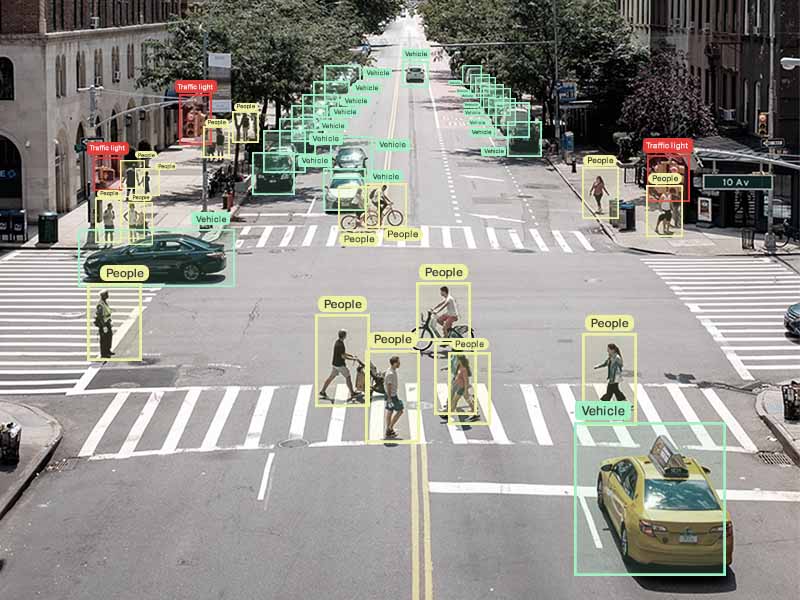
common models and data processing
Most image segmentation models use some sort of digital image processing to standardize original image data prior to training on the GPU. This can involve various filtering steps such as converting a given image to grayscale, normalizing pixel values and pixel intensities, clipping pixels at some threshold value, partitioning the input image, applying segmentation masks, applying a gaussian blur, implementing Otsu’s method for image thresholding, drawing bounding boxes around regions of interest for object detection, smoothing discontinuities, and other optimizations.
Once the image data has been processed, a classifier model is trained to divide the entire image into different segments using the class labels that have been provided. Popular image segmentation algorithms include U-Net, Mask R-CNN, and encoder/decoder models, all of which can be found on GitHub implemented in Python and other languages along with tutorials on how to use them. The training proceeds over many iterations, while optimization is performed using an algorithm such as gradient descent. Many image segmentation methods follow this framework.