Autonomous systems rely on LiDAR for accurate perception and spatial awareness to perform reliably in many structured driving situations. However, perception failures rarely occur under these predictable conditions. They usually appear in edge-case LiDAR scenarios, where the point cloud structure becomes sparse, incomplete, or inconsistent.

The primary challenge is that edge-case LiDAR data is difficult to capture consistently and is therefore underrepresented in curated training datasets. As a result, perception models trained on standard datasets often fail to learn to handle these conditions, leading to unstable detections in real-world environments. This gap between curated dataset coverage and deployment conditions continues to affect perception reliability in autonomous driving systems.
This article explains why edge-case LiDAR data matters for perception reliability and how edge-case dataset strategies help strengthen autonomous system performance across real-world operating environments.
Why Autonomous Systems Still Struggle in Real-World Conditions
Autonomous perception models perform consistently in frequently observed driving scenarios, but their reliability decreases in long-tail scenarios and edge cases. These situations often involve temporary road layouts, uncommon object configurations, irregular pedestrian movement patterns, or objects that appear only rarely in perception datasets.
In many cases, the difficulty lies in both behavioral complexity and how these situations are represented in sensor data. Occlusions, partial visibility, and sparse point returns can change how objects appear in the LiDAR point cloud, making them harder for detection models to interpret correctly.
Research on LiDAR-based 3D detection highlights that sparse point clouds and occlusion remain ongoing challenges that affect how reliably models interpret scene geometry.
Since these conditions occur less often in curated datasets, they introduce coverage gaps that limit how well LiDAR systems generalize beyond standard autonomous driving environments.
Why Edge-Case LiDAR Data is Critical for Autonomous Perception Reliability
Edge-case LiDAR data improves perception reliability by exposing models to conditions that differ from standard training. This helps models learn more stable representations of 3D structures and handle uncertainty better in real-world environments.
Here is why edge-case LiDAR data is important:
- Improves robustness in long-tail scenarios: Models generalize better beyond benchmark environments. They learn from rare LiDAR patterns. These include sparse returns, partial geometry, and unusual spatial layouts that are not common in training data.
- Reduces false positives and false negatives: This is especially important for reflective surfaces and rare objects. For example, reflective glass can appear as an obstacle when none exists (a false positive), while a partially occluded pedestrian may not be detected at all (a false negative). Edge-case data helps models learn to handle such variations more accurately.
- Enhances sensor-fusion reliability: Edge cases reveal alignment issues between LiDAR and cameras. This often happens under occlusion, timing mismatches, or viewpoint differences. For example, a pedestrian partially hidden behind a parked vehicle may appear clearly in camera images but only partially in the LiDAR point cloud. This can create inconsistent object boundaries across sensors. Training on these cases helps models learn how objects appear differently across modalities and improves consistency when combining LiDAR and camera detections.
- Supports safer real-world deployment: Edge-case scenarios help improve detection stability under uncertain conditions. Objects may be partially visible or poorly defined in the point cloud. Exposure to such cases improves prediction consistency.
- Accelerates validation and simulation readiness: Edge-case data improves testing realism. It includes low-density point clouds, motion artifacts, and environmental interference. These make validation closer to real-world conditions.
LiDAR Annotation Challenges Unique to Edge-Case Scenarios
Edge-case LiDAR data is harder to annotate than standard driving scenes. The main reason is that the geometry is often incomplete or unclear.
This creates several LiDAR annotation challenges.
- Labeling partially visible objects becomes difficult because object boundaries are not fully defined in the point cloud.
- Maintaining temporal tracking across frames is also challenging. Objects may change shape or visibility over time due to occlusion or motion.
- Rare scenarios often require extending label definitions. Standard ontologies may not fully cover unusual object types or edge behaviors.
- Sparse point clouds introduce ambiguity. Annotators must infer structure from limited spatial information.
- In multimodal setups, aligning LiDAR with camera and radar data adds another layer of complexity. Even small misalignments can affect label accuracy.
- Ensuring QA reliability adds another challenge. Edge-case datasets require more review cycles to ensure consistency and reliability.
Annotation quality becomes especially important when datasets contain uncertain geometry.
iMerit supports perception teams with structured 3D point cloud annotation workflows designed for edge-case LiDAR data. These workflows help expand coverage of rare scenarios and improve long-tail performance in autonomous systems.
Sensor-Level Challenges of LiDAR Edge Cases
Edge-case LiDAR scenarios also introduce challenges at the sensor level. These include :
- Sparse point cloud returns occur when fewer laser points are reflected back to the sensor. This reduces scene detail, especially for distant or small objects.
- Reflective surfaces can distort LiDAR signals. Materials such as glass, metal, or polished objects may cause irregular or misleading reflections.
- Occlusions and partial geometry appear when objects are only partly visible. This makes it harder to reconstruct full object shapes from the point cloud.
- Motion-induced artifacts occur when objects or the sensor are moving quickly. This can create stretched or misaligned point patterns
- Multimodal timing differences happen when LiDAR, camera, and radar are not perfectly synchronized. Even small delays can affect how fused data is interpreted.
These conditions reduce confidence in perception outputs, even when models perform well on benchmark datasets.
Building Edge-Case Coverage into the Perception Development Loop
Perception teams improve reliability by treating edge-case discovery as part of the dataset development loop. Instead of adding rare scenarios only during validation, teams identify and expand them continuously during model training. This usually happens through structured scenario mining, targeted LiDAR annotation, and iterative retraining.
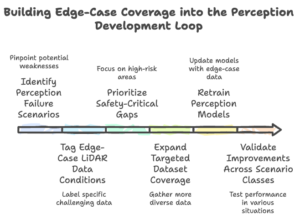
1. Identify Perception Failure Scenarios
Review model outputs to locate unstable detections. These often appear in sparse point clouds, under partial occlusion, or in reflective environments. Evaluation benchmarks alone do not always expose these weaknesses. Use scenario-based testing pipelines and simulation replay tools to surface failure patterns earlier in development.
Large-scale perception datasets expose models to diverse driving conditions, enabling slice-based evaluation across different environments such as cities, weather, and lighting. For example, the Waymo Open Dataset supports measuring performance variations across these conditions, helping identify scenarios where detection accuracy drops.
These insights are then used to guide targeted data collection, where additional samples are gathered from underperforming scenarios. This helps improve coverage of rare or challenging cases.
2. Tag Edge-Case LiDAR Data Conditions
Tag scenes based on how LiDAR signal quality changes in those situations. Common tags include sparse point cloud regions, partial object visibility, motion distortion, reflective interference, and sensor misalignment across frames. This helps you group similar perception failures together. You can then filter datasets by edge-case type during retraining and evaluate performance across specific LiDAR conditions.
Multimodal datasets such as nuScenes support this workflow by providing synchronized LiDAR, radar, and camera streams. This makes it easier to identify occlusion patterns, visibility changes, and cross-sensor inconsistencies before adding condition tags.
3. Prioritize Safety-Critical Gaps
Not all edge-case scenarios affect perception performance in the same way. Decide which conditions should be addressed first. Perception teams prioritize scenarios that affect detection continuity around pedestrians, cyclists, intersections, and merging traffic. These situations often combine occlusion, motion, and reduced point cloud density. As a result, they are more likely to introduce unstable detections than scenes with predictable vehicle motion.
Safety-relevant interaction events appear only rarely in curated driving datasets. Some complex interaction segments occur in less than 0.03% of recorded data. Because of this imbalance, expanding the dataset size alone does not resolve coverage gaps. Targeted scenario selection is usually more effective than uniform scaling.
4. Expand Targeted Dataset Coverage
Expand coverage around those exact signal conditions rather than collecting more general driving data. This often involves mining fleet logs using scenario filters, replaying difficult segments in simulation, and assigning focused annotation effort to scenes with sparse geometry or partial object visibility.
Teams may also generate controlled variations through synthetic augmentation to increase the representation of rare spatial layouts. The goal at this stage is dataset growth in coverage. Increasing exposure to rare conditions helps detection models learn from the same structures that previously caused instability.
5. Retrain Perception Models
Retrain models using sampling strategies such as reweighting rare driving scenarios and hard-example mining, which prevent dominant driving scenes from overshadowing rare conditions. Without this adjustment, common highway and lane-following sequences continue to shape most model updates.
Scenario-balanced sampling increases the influence of sparse returns, reflective interference, and partial object geometry during training. Increasing environmental and scenario diversity improves detection stability across operating regions. This makes targeted edge-case expansion more effective than scaling dataset size alone.
6. Validate Improvements Across Scenario Classes
Instead of checking overall accuracy, measure performance separately in occlusion-heavy scenes, sparse point cloud regions, reflective infrastructure zones, and complex interaction environments. This makes it easier to confirm whether additional edge-case LiDAR coverage improves performance in the same conditions where failures originally appeared.
Scenario-level validation closes the loop between failure discovery and dataset expansion. It shows whether the added coverage improves perception behavior in deployment-like environments rather than only improving benchmark results.
Scaling Edge-Case Intelligence with Specialized Data Pipelines
As edge-case coverage grows, use structured data pipelines to maintain consistent annotation and validation across large LiDAR datasets. Don’t treat edge cases in autonomous vehicles as isolated samples. Organize them into repeatable workflow stages.
Here is how it works:
- Use scenario-aware annotation workflows to group labeling tasks by failure type. Separate occlusion-heavy intersections, sparse point cloud regions, and reflective infrastructure into different scenario buckets instead of mixing them in the general scene annotation.
- Run temporal consistency validation across sequential LiDAR frames to keep object identity stable over time. Apply this especially in motion-heavy scenes where visibility changes across frames.
- Extend ontology customization when standard label classes are not enough. Define additional categories for partial objects, temporary road elements, and unusual vehicle shapes that do not fit existing schemas.
- Apply rare-class labeling to focus annotation effort on low-frequency but safety-relevant cases. This includes cyclists in low visibility, pedestrians emerging from occlusion, and uncommon interaction patterns at intersections.
- Perform multi-sensor alignment QA across LiDAR, radar, and camera streams in edge-case sequences. Correct timing or spatial drift when sensor synchronization is inconsistent.
- Use structured edge-case dataset expansion to connect these steps into a repeatable workflow for scaling coverage across new datasets instead of handling scenarios one by one.
Want to see how this works in practice? See how iMerit helped a leading automotive technology company accelerate 3D sensor fusion annotation.
Conclusion
Real-world autonomous systems depend on much broader scenario coverage than what benchmarks can provide. Edge-case LiDAR data plays a central role in exposing rare but critical perception failures that are not visible in standard training distributions.
- Edge-case LiDAR data represents rare and safety-critical scenarios that are often missing from benchmark datasets but frequently appear in real-world conditions.
- Broader scenario coverage improves perception reliability more effectively than increasing dataset size alone.
- Structured datasets make it easier to validate performance across simulation and real-world environments in a consistent way.
- Long-tail performance remains a key factor in determining whether autonomous systems are truly deployment-ready.
iMerit’s hybrid approach, powered by Ango Hub and the 3D Point Cloud Services, supports perception teams in handling complex edge-case LiDAR data at scale. We combine automated pre-processing, expert-led annotation, and structured validation workflows to ensure rare and high-impact scenarios are accurately captured.
Talk to an iMerit expert today to learn how we can help you refine datasets and reintegrate edge cases into model training for more reliable real-world performance.