Text Annotation Tool
From raw text to structured truth, at scale

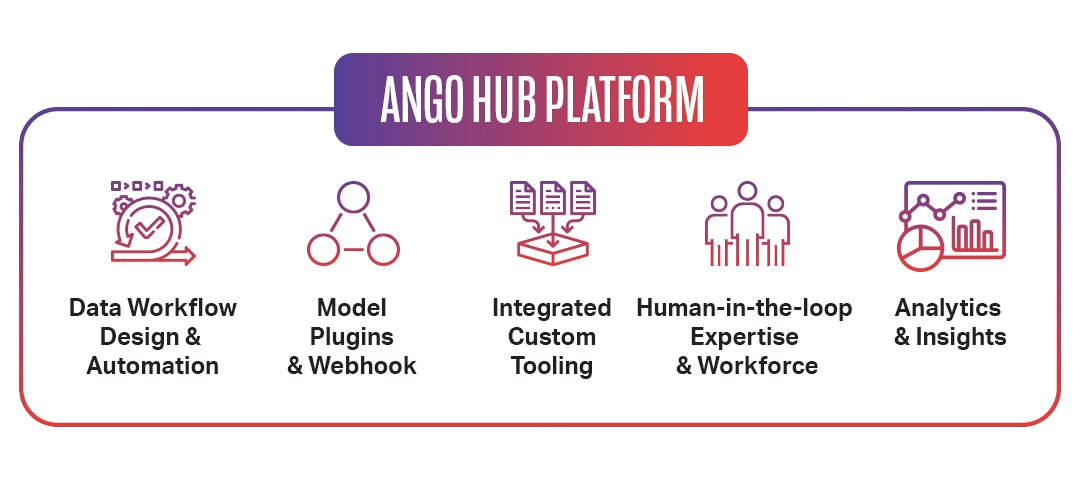
WHAT ANGO HUB OFFERS
Ango Hub supports text annotation as part of a broader AI data platform, combining workflow automation with expert-in-the-loop delivery. iMerit works on your text and document data to produce high-quality ground truth for NLP and LLM use cases, with consistent schema adherence from labeling through review.
WORKFLOW MANAGEMENT
BUILT-IN QUALITY CHECKS
AUTOMATION
INTEGRATIONS
ANALYTICS
SECURITY AND GOVERNANCE




USE CASES
LLM AND CHATBOT TRAINING DATA
Label intents, entities, and conversation outcomes to train assistants that follow instructions and respond accurately.
SEARCH RELEVANCE AND RANKING
CONTENT MODERATION
DOCUMENT AI FOR FINTECH AND INSURANCE
CUSTOMER SUPPORT ANALYTICS
COMPLAINCE AND RISK DETECTION
INDUSTRIES WE SERVE

HEALTHCARE

FINTECH AND INSURANCE

TELECOM

RETAIL AND E-COMMERCE

GOVERNMENT AND PUBLIC SECTOR

TECHNOLOGY PLATFORMS
Train and evaluate NLP and LLM systems with high-quality labeled text at scale.
WHY CHOOSE iMERIT

EXPERT-IN-THE-LOOP EVALUATION
TECHNOLOGY & SCALE

SECURITY
SCALING
HUMAN IN THE LOOP
CASE STUDY
.American Ancestors partnered with iMerit to digitize and index more than 1,300 books of sacramental records containing vital information from 1789 to 1900,. Because the project’s massive scale exceeded the capacity of their traditional volunteer-led approach, the organization utilized iMerit’s specialized experts to transcribe and assess complex handwritten documents,. The result was the creation of a searchable database featuring over 14 million names, allowing users worldwide to discover tangible connections to their family history.
Frequently Asked Questions
What text annotation tasks can Ango Hub handle for NLP and LLM training?
Ango Hub supports the full range of NLP and LLM data needs: named entity recognition (NER), relation extraction, text classification, intent and entity labeling for chatbots, sentiment analysis, document field extraction, search relevance judgments, content moderation labeling, and compliance and risk detection. Whether you're building a domain-specific LLM or tuning a general-purpose assistant, the platform is built for schema-consistent, high-volume text annotation.
How does iMerit maintain consistency across large-scale text annotation programs?
Consistency starts with schema. Ango Hub enforces structured workflows with centralized guidelines, pre-label imports, and adjudication processes that resolve annotator disagreements systematically. iMerit's reviewers handle edge cases, domain terminology, and ambiguous language with defined rules — so entity boundaries, classification decisions, and relation labels stay consistent across thousands of tasks and multiple annotators.
Can the text annotation tool support document AI use cases in regulated industries like healthcare or finance?
Yes. iMerit's text annotation platform is actively used in healthcare (clinical text coding, triage, summarization), fintech and insurance (claims processing, risk signal detection, entity extraction from policies), and government (document processing, compliance monitoring). The platform supports PII-aware workflows, governed access, and enterprise-grade security for teams working with sensitive or regulated source data.
Does the text annotation platform support pre-labeling or model-assisted annotation?
Yes. Ango Hub allows you to import model outputs and pre-labels to jump-start annotation, which dramatically reduces manual effort on high-volume programs. Teams can use automation to handle the straightforward cases and route ambiguous or difficult tasks to human reviewers — creating a scalable human-in-the-loop pipeline that improves both speed and accuracy.
What industries and use cases does iMerit's text annotation tool serve?
iMerit's text annotation platform serves AI and NLP teams across technology platforms (LLM and chatbot training), healthcare (clinical documentation), fintech and insurance (document AI), retail and e-commerce (search relevance, catalog labeling), telecom (intent routing, churn analytics), and government (case management, compliance). Any team that needs structured, reliable labeled text for model training or evaluation can benefit from iMerit's combination of Ango Hub and expert delivery.