Namita Pradhan walks into iMerit’s Bhubaneshwar office on a sunny and humid day. She begins her work of identifying specific pathological abnormalities in a series of high-resolution endoscopy slides. She spends her day dealing with dozens of anatomical images, marking and classifying precise abnormalities with intense concentration.
Namita is one of several medical data labeling experts at iMerit who have gained significant experience in reviewing medical images, slides, and videos and identifying and classifying pathologies. This work, done at high accuracy, is then used to train Machine Learning algorithms to pursue the same goal. This is a specialised expertise, exotic, and hard-won, particularly as Namita and her teammates do not have a background in medicine.
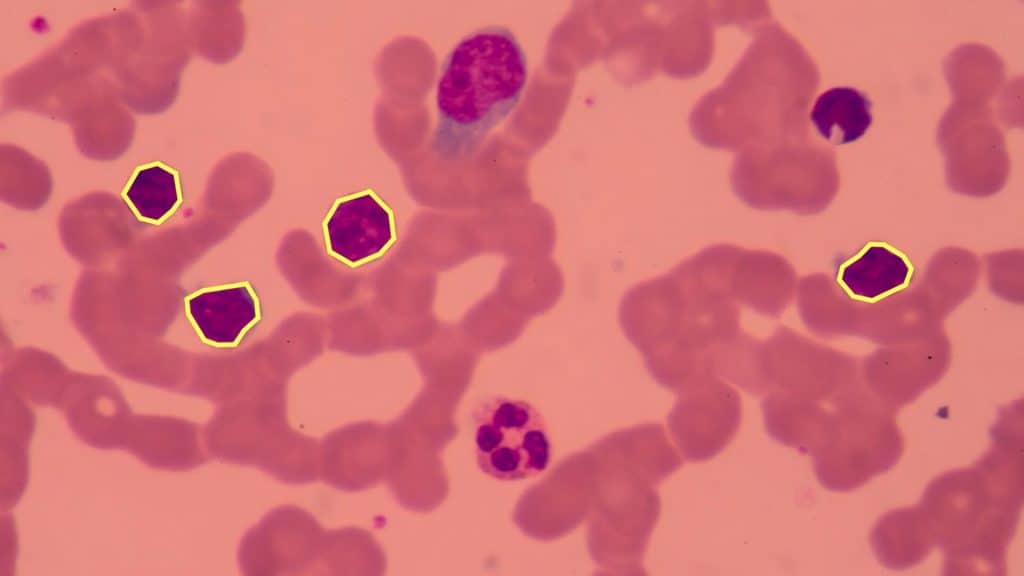
Machine Learning algorithms operate by learning from thousands of training samples which have been already annotated by humans – in essence, flash cards for AI. This is fine when the task involves generalised situations like identifying everyday objects in images or text. It becomes a bottleneck when the task is a specialised one, such as a medical pathology or a legal contract. The prohibitive cost of labeling at scale by medical experts can deter companies from initiating ML projects.
We can eliminate this bottleneck if there is a scalable process for transforming data labeling generalists into specialists. This can be achieved in an enterprise setting such as iMerit’s, with the right mix of talent, skilling, and knowledge transfer.
The “focused and deep” curriculum covers medical lexicon, pathology, spatial orientation, and data manipulation. With medical data, pattern recognition and memorization techniques enhance the conceptual knowledge.
The first point of contact is a Solution Architect (SA) who is a medical domain expert. The SA bridges the exotic medical world with the focused but deep approach of the expert data labeler. This work includes:
- Unpacking the use case to be generalist-friendly
- Challenging and distilling definitions to ensure clarity
- Building adequate but not excessive context
- Questioning edge cases and anticipating areas of confusion
It’s no coincidence that these steps exactly mirror what the Machine Learning algorithm needs.
Next, we have the data labeler. Not everyone can be an expert data labeler. Professionals like Namita have an endless appetite for learning, craftsman-like attention to detail, and a knack for detecting patterns and outliers.
Finally, this is backed by a robust and agile skilling structure which focused on learning by example and learning by exception.
When generalists become specialists
The team members are onboarded in a three-week phase. The “focused and deep” curriculum covers medical lexicon, pathology, spatial orientation, and data manipulation. With medical data, pattern recognition and memorization techniques enhance the conceptual knowledge. We test a specific aptitude for tasks which involve medical images devoid of real-world context. It’s a bit like sifting through abstract art all day long. Namita says it took some time to settle into this aspect of the work, but it has now become second nature.
When a project begins, the specialist is custom-trained using live-demos, videos, models, and instruction guides dealing with the specific pathologies of the project. She is also trained in using the annotation tools and custom software, some of which is familiar from past projects. Labeling and annotation are iterative processes, so a contributor becomes progressively conversant with the scope of the work. For instance, a contributor is instructed not to mark a pathology unless she is completely certain about its location. While marking boundaries, she is taught to mark only the sections that are clearly seen. Her confidence grows with repeated exposure to a similar set of images.
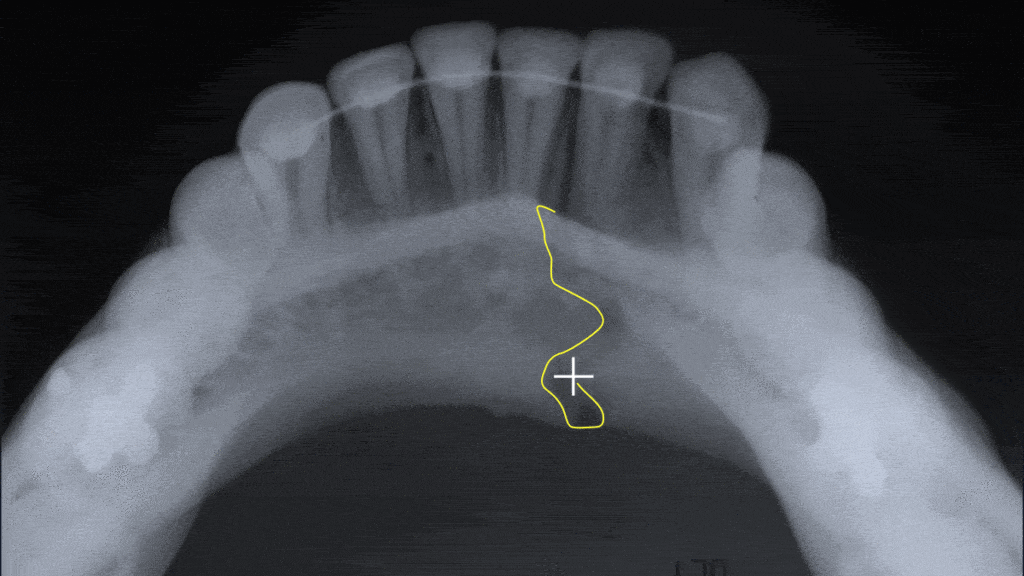
The process is not without challenges, especially in the early days of the project. The stakes are quite high. Tricky edge cases need to be referred to the internal medical expert and possibly escalated to the customer. A culture of being able to say “I don’t know for sure”, without fear or judgment, is valuable.
Edge cases build a disproportionately deeper understanding of the problem space and make the job interesting. They simultaneously boost the judgment and instincts of the labeling expert. The finely honed instincts become crucial when looking at a series of images which may not follow the correct sequence. This makes it hard to zero in on the exact location of the pathology. Solving this puzzle gets easier with experience.
A new breed of micro-learners
It is challenging but rewarding work. Namita is strongly motivated by the real-world applications of her work, and the positive impact she will have on a patient’s health. She even reads medical material on her own time to expand her conceptual understanding. Her teammate, Chinmayee Swain, engages with the projects on a more personal level. The technology she is helping build could someday benefit her own community. This level of investment and interest motivates a team that tackles dense information with high rates of accuracy.
Namita and Chinmayee represent a new breed of agile micro-learners. They learn by patterns and by doing, and has a sharp instinct for edge cases. They look for ways to break the instructions provided by the subject expert. They can do this because she has no preconceived assumptions or biases. They are looking at the problem in a pristine context.
As the day winds down, the team signs out with a sense of accomplishment. Medicine is a respected field globally. Being associated with it as niche medical data experts is motivational and aspirational. In return, the team’s work enables the medical gurus to push the boundaries of their profession.
How iMerit helps create healthcare data labeling experts
- Data labelers are hired for the medical domain based on certain key qualities.
- They go through a three-week training process. The curriculum covers medical lexicon, pathology, spatial orientation, and data manipulation.
- They are staffed on a specific medical project.
- A Solution Architect unpacks the use case with the customer and bridges the domain knowledge.
- The SA and customer impart project-specific training. This includes live demos, videos, models, and instruction guides.
- The team tests processes and validates instructions in the first phase.
- Tricky edge cases are referred to the SA and possibly escalated to the customer.
- The Project Manager and QC leads track and evolve the quality through all iterations.
Click here to watch iMerit Solutions Architect Dr Sina Bari discuss the role of expertise in healthcare data during the AIMed conference.