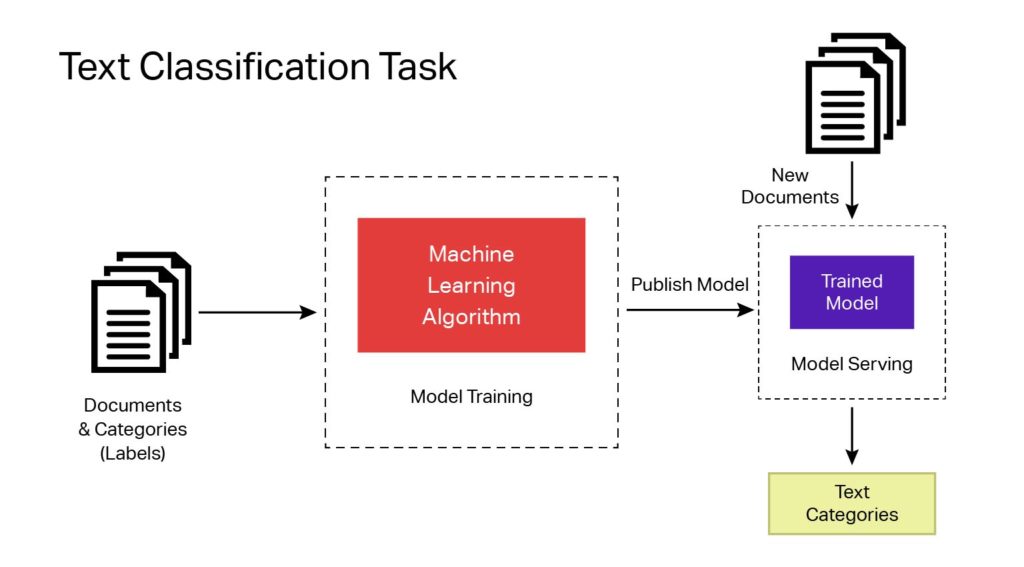
Text classification is the fundamental machine learning technique behind applications featuring natural language processing, sentiment analysis, spam & intent detection, and more. This critical function is especially useful for language detection, which allows organizations and individuals to understand things like customer feedback in ways that will inform future approaches.
Build your own proprietary text classification dataset. Get a quote for an end-to-end data solution to your specific requirements.
Talk with an expertTraining an ML model for text classification brings with it challenges. That’s why we at iMerit have compiled this list to ensure you have a seamless and highly-efficient journey getting it done.
Text Classification Dataset Repositories
TREC Data Repository: This data repository began at the Text Retrieval Conference which began as a means to support ongoing research within the information retrieval committee. This repository contains a breadth of data including research papers relating to NLP, news articles, spam, and question/answer sets, to name a few. Users will notice the pre-2000s UI of the website. Don’t let this deter you; this text classification dataset is a winner.
Recommender Systems Datasets: UCSD’s Julian McAuley, the computer science Associate Professor, essentially curated this text classification dataset repository. While he didn’t do it himself, those who collected and compiled the information within this text classification dataset repository did so on the merit of his research. The information contained within features social networking data, product review data, social circles data, and of course question/answer data.
GroupLens Datasets: The research lab known as GroupLens specializes in the areas of online communities, digital libraries, edge technologies, geographic information systems, and recommender systems. The information contained within this text classification dataset repository include rating data from movie websites, wiki recommendation data, book ratings from BookCrossing, and more.
Kaggle Text Classification Datasets: Kaggle is the king when it comes to searching for open datasets. As such anyone looking for a text classification dataset should always stop here first as the site contains 19,000+ of them. There’s also a slew of competitions featuring high-paying prizes that Kaggle hosts to encourage ongoing text classification dataset generations via projects and research.
niderhoff/nlp-datasets: This GitHub repository by niderhoff offers an extensive list of free, publicly available datasets with text data specifically curated for Natural Language Processing (NLP) tasks. It includes datasets in various languages besides English, making it a valuable resource for multilingual projects.
UCI Machine Learning Repository: It is a well-established archive of datasets for machine learning tasks, including text classification. It offers a wide variety of datasets categorized by various domains, making it easy to find datasets relevant to specific needs.
Papers with Code – Datasets: Another fantastic platform for exploring research papers and their associated datasets. Users can search for papers on text classification and find datasets they use for their experiments. This allows users to stay up-to-date with the latest research and utilize similar datasets for their projects.
Sentiment Lexicons for 81 Languages: It contains several languages, from Afrikaans to Yiddish. It includes both positive and negative sentiment lexicons for 81 languages.
Sentiment Analysis and Review Datasets
Twitter US Airline Sentiment: Twitter data on US airlines dating back to February of 2015 that’s already been classified based on sentiment class (positive, neutral, negative). This text classification dataset contains roughly 15,000 tweets pertaining to about six different commercial airlines.
Opin-Rank Review Dataset: This car dataset features a range of reviews around models manufactured between 2007 and 2009. It also features hotel review data, and contains Tripadvisor review data across 259,000 hotels within 10 cities with 80-700 hotels accounted for in each city. There’s also car review data (Edmunds car review) between 2007 and 2009 which comes with things like publication dates, author names, and written feedback.
Large Movie Review Dataset: Straight from the boon of the Stanford AI Laboratory, this movie review dataset features 25,000 reviews of highly-polarizing films along with another 25,000 reviews specifically designed for training.
Multi-Domain Sentiment Analysis Dataset: A treasure trove of positive and negative Amazon product reviews (1 to 5 stars) for older products.
Amazon Product Data: Featuring 142.8 million Amazon review datasets, this SA dataset features reviews aggregated on Amazon between 1996 and 2014.
Paper Reviews: This dataset is composed of English and Spanish language reviews around computing and informatics. The dataset is evaluated using a five-point scale with -2 being the most negative and 2 being the most positive.
Stanford Sentiment Treebank: This dataset contains 10,000+ pieces of Stanford data from HTML files of Rotten Tomatoes. Evaluated between 1 and 25, where one is the most negative and 25 is the most positive.
IMDB Movie Reviews Dataset: This dataset contains 50,000 movie reviews from IMDB. The positive review has a score of ≥ 7 out of 10, while the negative review has a score of ≤ 4 out of 10, and only highly polarized reviews are considered in this dataset.
Online Content Evaluation Datasets
Spambase Dataset: Nobody likes spam. This Spambase text classification dataset contains 4,601 email messages. Of these 4,601 email messages, 1,813 are spam. This is the perfect dataset for anyone looking to build a spam filter.
Stop Clickbait Dataset: This text classification dataset contains over 16,000 headlines that are categorized as either being “clickbait” or “non-clickbait”. Naturally, the clickbait articles are pulled from clickbait perpetrators like BuzzFeed, while the non-clickbait bits and bobs are from reputable and highly-respected news sources like The Guardian.
Hate Speech and Offensive Language Dataset: There’s no shortage of hate speech online. This text classification dataset features hate-speech gathered from social media. It has been classified as either containing hate-speech, only offensive language, or neither. Do note that this data contains offensive content, none of which we endorse outside of the value it presents to anyone training a model.
The Blog Authorship Corpus: This 2004 collection of over 650,000+ blog posts was gathered from blogger.com with over 19,000 bloggers at work utilizing 140 million words.

News Datasets
The 20 Newsgroups Dataset: This popular dataset is perfect for anyone looking to experiment with text classification. It contains 20,000 unique newsgroup documents that have been partitioned between 20 separate newsgroups.
AG’s New Topic Classification Dataset: This impressive collection of 1M+ articles was gathered by an academic news search engine across 2,000 separate news sources. It contains a whopping 30,000 training samples and 1,900 testing samples.
Reuters Text Categorization Dataset: Containing 21,000+ Reuters documents gathered from Reuters’ newswire in 1987, this text classification dataset has a training set of 13,625 documents. It also comes with a testing set of 6,188 documents.