Reinforcement Learning from Human Feedback (RLHF) is a powerful way to train AI systems. It uses human input to guide AI behavior, making models more helpful and safe. However, human feedback can be noisy, biased, or conflicting due to subjective interpretations, cultural biases, and personal beliefs. This inconsistency can confuse AI models, leading to unpredictable outcomes or reinforcing biased behaviors. These challenges make it harder to align AI with user intentions.
Researchers are addressing this with consensus logic, which combines multiple opinions for better decisions, and escalation mechanisms, which flag tough cases for expert review. These methods help filter out errors, reduce bias, and improve AI learning.
Let’s break down how consensus and escalations can make RLHF more accurate and trustworthy to create AI systems that better understand and serve human needs.
Understanding RLHF and Its Limitations
RLHF trains AI models using human input to improve responses. Instead of relying only on programmed rules, the model learns from real-world judgments. This helps AI align with human expectations in areas like chatbots, content filtering, automated decision-making, and many more.
For example, OpenAI’s ChatGPT uses RLHF to refine answers based on user preferences. AI models in e-commerce also use it to improve product recommendations by learning from customer interactions.
Despite its benefits, RLHF faces several challenges:
- Subjectivity and Bias : Human feedback is often inconsistent, with different annotators interpreting responses in varying ways. Research shows that labeler agreement on subjective tasks like toxicity detection can be very low.
- Defining “Correct” Responses: There isn’t just one correct answer in many AI tasks. For example, what counts as an “engaging” conversation or an “appropriate” response can differ depending on the user and the situation.
- Overfitting to Annotator Preferences : AI models may learn to optimize for individual annotators’ opinions rather than broader, objective quality standards. This can reduce generalization and introduce bias.
- Scalability Issues : Effectively managing RLHF at large scales requires structured feedback loops and automation. Without proper systems, quality control becomes difficult, and inconsistencies can persist.
The Role of Consensus Logic in RLHF
Consensus logic is a method for improving the reliability of human feedback in RLHF. It reduces bias by aggregating responses from multiple annotators instead of relying on a single opinion. This ensures that AI models learn from well-rounded, balanced feedback.
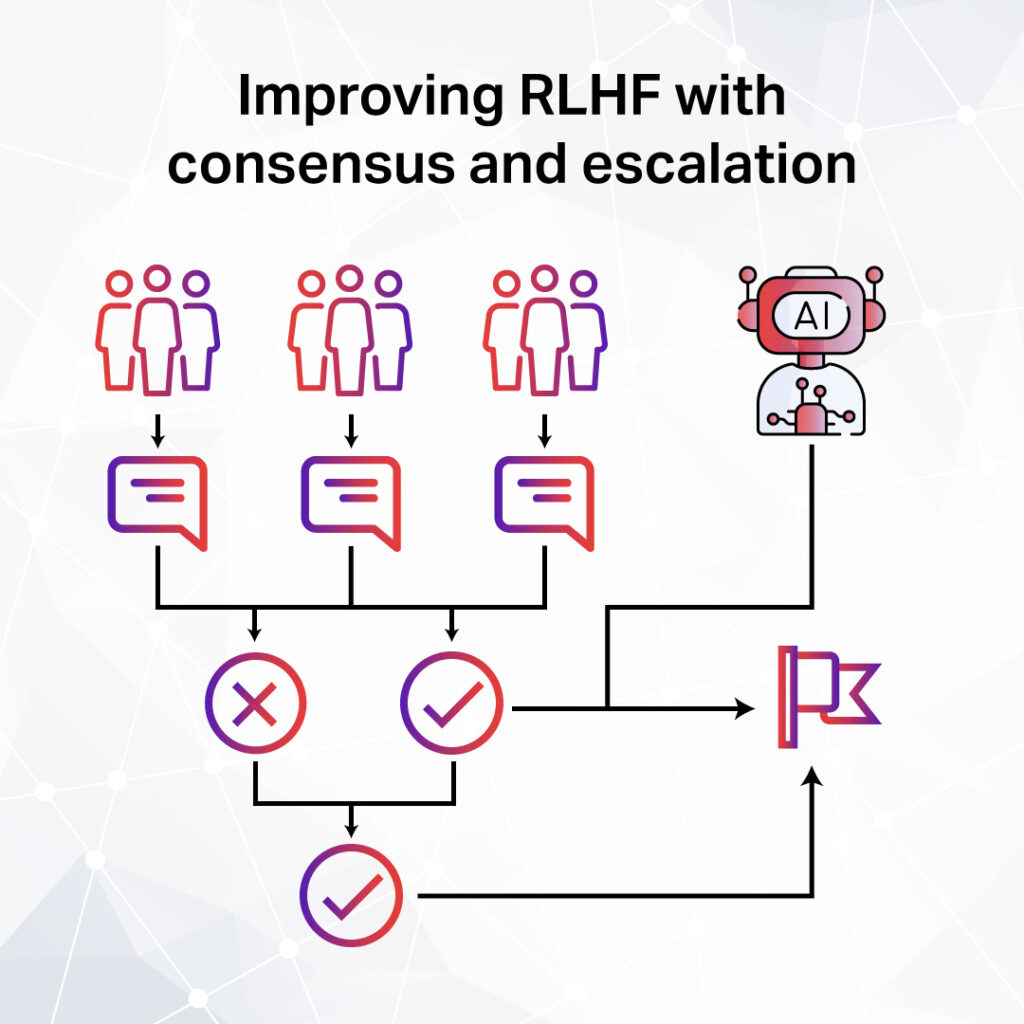
For example, a chatbot learning customer service responses might get three different ratings on the same answer. Without consensus logic, the AI could reinforce misleading feedback. A structured approach ensures it follows the most accurate guidance.
How Does It Work?
Without consensus, human feedback can be inconsistent. Consensus logic creates stability by aligning feedback across multiple sources. It ensures that only well-validated feedback is used for training. It improves:
- Reliability: AI models learn from consistent patterns, not individual biases.
- Fairness: Multiple perspectives reduce the risk of a biased dataset.
- Scalability: The process allows large datasets to be annotated more efficiently.
Implementing Consensus Logic
Here is how to implement consensus logic:
- Majority Voting: The simplest method. AI decisions are based on the most common feedback. This works well for straightforward tasks but may ignore expert input.
- Weighted Scoring : Not all raters have the same expertise. Some feedback carries more weight, especially from experienced reviewers. This improves decision quality in complex tasks.
- Confidence Scoring : Each decision gets a “certainty” rating based on agreement levels.
- AI-Assisted Consensus : Machine learning can detect disagreements and flag uncertain cases. It helps filter out extreme opinions and refines AI training data.
These methods allow RLHF to produce more consistent, fair, and high-quality training data.
Escalation Mechanisms: Handling Disagreements and Edge Cases
Even with consensus logic, some cases remain unclear. These cases may cause disagreements among annotators or involve complex, high-stakes decisions. If not addressed, they can introduce noise into AI training. Escalation workflows ensure that tough decisions are sent to higher-level reviewers, preventing incorrect training data from negatively impacting AI performance.
Identifying the Problem
Complex AI tasks often involve edge cases that annotators can’t easily resolve.
For example:
- Medical AI models may require input from doctors for ambiguous diagnoses.
- Legal AI tools might need expert review for nuanced contract terms.
- AI chatbots often struggle with subjective language interpretations.
These cases might receive random or inconsistent labels without escalation, reducing AI accuracy.
Designing an Escalation Workflow
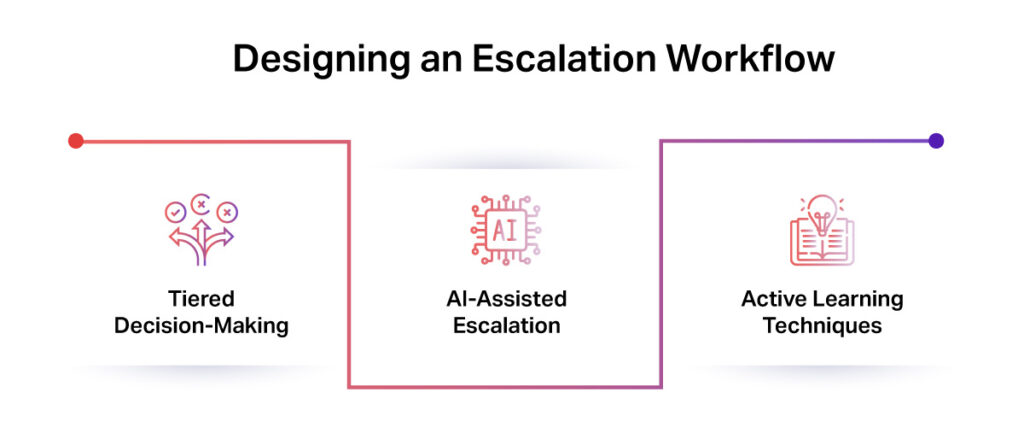
Here is how to design an escalation workflow:
- Tiered Decision-Making: Simple cases get resolved automatically. Complex cases move to human reviewers. If needed, domain experts make the final call.
- AI-Assisted Escalation: Models detect anomalies or disagreements and trigger a review process. This prevents flawed data from entering the training pipeline.
- Active Learning Techniques: The AI flags uncertain cases and requests targeted feedback. Over time, this improves its handling of similar challenges.
Combining Consensus Logic and Escalations
Consensus logic ensures broad agreement before feedback is used in AI training. Escalation mechanisms handle disagreements and complex cases. Together, they create a structured approach to improving RLHF. Here’s how they complement each other:
The Screening Process
Consensus serves as the first filter, efficiently handling most straightforward cases. When multiple raters agree (typically 70-80% of the time), the system makes immediate updates, keeping the training process fast and efficient.
The Safety Net
Escalations handle cases that consensus can’t resolve. These include ambiguous, controversial, or high-stakes decisions, which make up 15-25% of evaluations. These cases receive expert attention to ensure accuracy.
The Feedback Loop
Escalated decisions flow back into the system, improving both the AI model and future consensus outcomes. This creates a continuous cycle of improvement. As the model refines its understanding, it becomes better at handling ambiguous cases in the future.
Combining consensus logic and escalations creates a more reliable and effective RLHF process. Here are some of their main benefits:
- Better Model Alignment : AI learns from feedback that reflects a broad consensus, reducing the risk of misalignment with human intent.
- Reduced Bias : Incorporating diverse perspectives helps the system avoid overfitting to individual annotators’ opinions, resulting in fairer AI decisions.
- Scalability and Efficiency : Automated consensus speeds up routine feedback processing, while escalation mechanisms ensure that only the most complex cases require human intervention.
- Improved AI Safety: Structured review processes help prevent harmful outputs, ensuring the AI remains trustworthy and aligned with ethical guidelines.
Technical Implementation
A well-designed RLHF system must integrate both consensus logic and escalation mechanisms to ensure reliable feedback processing. This requires structured data collection and robust algorithmic approaches.
Data Collection and Annotation
To support consensus and escalations effectively, feedback systems should be designed with:
- Multiple Reviewers Per Task: Aggregating feedback from different annotators improves accuracy and reduces individual bias.
- Automated Disagreement Detection : AI should flag conflicting responses for further review, ensuring only high-confidence data is used for training.
- Expert Review Layers : Complex or high-risk decisions should be escalated to domain specialists for final evaluation.
Algorithmic Approaches
Implementing the right algorithms ensures that AI models learn from well-structured feedback. Key approaches include:
- Consensus-Building Algorithms : Methods like majority voting, Bayesian aggregation, and confidence-weighted scoring improve response consistency.
- Escalation Protocols : AI-driven anomaly detection and active learning strategies identify uncertain cases, triggering additional human review where necessary.
Integrating these technical solutions makes RLHF more scalable and better aligned with human expectations. Several existing tools and services can streamline the implementation of consensus and escalation workflows in RLHF. For organizations implementing RLHF, specialized services like iMerit provide end-to-end solutions tailored to reinforcement learning from human feedback. Their RLHF services offer:
- Expert Annotation Teams: Trained raters who specialize in evaluating AI outputs for alignment and safety.
- Domain-Specialized RLHF: Feedback pipelines focused on specific industries such as healthcare, legal, and compliance.
- Benchmarking and Guidelines: Custom benchmarks and detailed guidelines ensure consistent performance throughout the process.
iMerit’s approach ensures high-quality human feedback at scale, which is critical for refining AI behavior while maintaining ethical standards.
Challenges and Limitations
When implementing consensus and escalation systems, real-world challenges may emerge. Here is what to watch for:
Over-Reliance on Consensus Leading to Groupthink
Consensus logic improves reliability, but it can also suppress diverse viewpoints. When annotators converge too easily, the AI may fail to learn from minority perspectives.
To address this, weighted aggregation can be introduced, giving more influence to experienced annotators while still considering varied inputs. Encouraging controlled diversity in reviewer selection helps capture a broad range of perspectives.
Delays Caused by Escalation Processes
Escalation workflows improve accuracy, but they slow down feedback loops. If too many cases require human intervention, training efficiency suffers.
AI-assisted escalation can help filter out low-risk cases automatically. Setting priority levels ensures that only critical disagreements reach human experts, speeding up the process.
Balancing Speed vs. Deliberation in Real-Time Systems
Some AI models require immediate responses, making lengthy review processes impractical. However, prioritizing speed over deliberation increases the risk of errors.
Tiered decision-making can be implemented, where routine cases rely on consensus, and escalations are fast-tracked based on impact severity. Active learning can also refine decision thresholds over time to improve decision-making efficiency.
Wrapping Up
Consensus logic and escalation mechanisms are vital for improving RLHF. Consensus reduces bias and ensures reliable feedback, while escalations resolve conflicts and handle edge cases. Together, they create stronger, more aligned AI models.
Next-generation RLHF systems will require even more adaptive approaches, integrating real-time feedback, active learning, and domain-specific expertise. Automating parts of consensus and escalation will boost efficiency without sacrificing accuracy.
iMerit simplifies this process with specialized RLHF solutions, combining expert annotation, automated quality control, and real-time performance tracking. Their work in retrieval-augmented generation (RAG) for healthcare chatbots demonstrates the value of real-time feedback, ensuring AI models receive high-quality, domain-specific training.
AI teams should adopt these strategies to build more trustworthy systems. Refining feedback loops helps create models that better align with human intent while remaining scalable and robust. Leverage iMerit’s cutting-edge RLHF solutions to build smarter, more adaptable AI models.