In 2022, the global autonomous vehicle (AV) market was valued at USD 1.5 trillion. By 2030, it is projected to grow nearly ninefold to USD 13.6 trillion, expanding at a 32.3% CAGR. Asia-Pacific already commands over 50% of this share, showing how quickly adoption is accelerating in key regions.

This isn’t just a financial trend; it reflects a fundamental shift in how people and goods will move. The key to unlocking this future, however, lies in one critical capability: a vehicle’s ability to perceive the world with the precision and reliability of a human driver.
This blog post will discuss how a modular pipeline handles the complex task of object detection and localization in a multi-sensor configuration. We will examine how this system performs in real-world scenarios, evaluate its results on large-scale datasets, and discuss why high-quality data annotation is essential for developing a high-performing perception system. At iMerit, we solve real-world problems that arise when building scalable, regulatory-compliant tools, with a workforce that includes domain experts with experience in complex workflows.
Introducing Autonomous Vehicle Perception
At its core, an autonomous vehicle’s ability to “see” the world is known as perception. It is the process of using various sensors to detect and understand the surrounding environment, much like a human driver uses their eyes and ears. This system must identify everything from other vehicles and pedestrians to traffic signs and road markings with incredible speed and accuracy.
The journey of AV perception has evolved significantly with the introduction of new technologies like cameras and LiDAR (Light Detection and Ranging). The evolution of these systems has been driven by advances in object detection models such as YOLO (You Only Look Once), Faster R-CNN, and SSD (Single Shot Detector), with the true breakthrough coming with the adoption of deep learning architectures like ResNet, EfficientDet, and Vision Transformers (ViTs).
In the AV domain specifically, specialized perception and fusion models have emerged. LiDAR-based methods like PointPillars enable accurate 3D object detection, while multi-sensor fusion approaches such as BEVFusion, DeepFusion, and TransFuser combine camera and LiDAR data to deliver a holistic understanding of the environment.
The modern challenge remains: seamlessly fuse all this data to create a robust perception system. A key component is data annotation, which requires precise alignment of data from different sensors and demands specialized tools and deep domain knowledge. Our teams are guided by clinical standards and reviewed through expert-in-the-loop workflows that allow feedback and learning, to ensure that the datasets powering these systems reflect how real clinicians make decisions.
Understanding Unresolved Challenges
Despite major advancements, autonomous vehicle (AV) perception systems still face unresolved hurdles. These aren’t minor technical glitches; they represent fundamental gaps that directly impact safety, scalability, and public trust. The ability of an AV to reliably perceive its environment, under any conditions, is the core issue limiting widespread deployment.
Key Hurdles in Perception
Identifying these challenges is the first step toward building a more robust and trustworthy system. The primary issues include:
- Occlusions: Objects hidden behind others, such as a cyclist behind a truck.
- Complex Environments: Crowded intersections with unpredictable pedestrian behavior.
- Weather and Lighting: Fog, rain, and nighttime conditions degrade sensor performance.
- Sensor Trade-offs: Cameras provide rich semantic detail but lack depth; LiDAR offers precise geometry but limited classification.
Why Rethink the Approach?
Given the persistent challenges in AV perception, a critical concern remains: conventional approaches fall short. The industry has largely relied on three architectural paradigms, each with its own merits and inherent limitations that prevent a truly holistic understanding of the world.
Limitations of Traditional Architectures
- Camera-first systems are excellent in classification and identification of what an object is, but struggle with depth accuracy. Without precise spatial information, they cannot reliably determine an object’s exact location and distance, which is critical for safe maneuvering.
- LiDAR-first systems provide precise geometry and distance data, excelling in creating detailed 3D maps of the environment. However, they lack the rich semantic context to identify objects, often annotating only the person in a person-with-bicycle scenario while missing the bicycle.
- Early fusion merges raw sensor data at the outset, aiming to leverage all information simultaneously. On the downside, it can introduce significant noise and complexity, making it difficult to debug errors and isolate the root cause of a perception failure.
The structural limits of these approaches necessitate a new way of thinking, and that is what iMerit is providing. What’s needed is a modular, step-by-step pipeline that can sensitively integrate the strengths of different sensors, isolate problems, and evolve with new advances. This is the foundation for a perception system that is not just functional, but truly reliable.
How the System Works:
Our proposed framework organizes perception into six sequential stages, each solving a specific challenge. This pipeline is not a rigid, all-or-nothing system; instead, it’s a flexible, modular design that allows for continuous improvement.
1. Data Preparation & Synchronization
The first step involves a crucial process of aligning data from multiple sensors, such as cameras and LiDAR, to the same timestamps. This synchronization prevents mismatched frames and ensures that the system is always working with a consistent view of the world, creating the foundation for accurate multimodal fusion.
2. 2D-to-3D Segmentation-Based Detection
Building on synchronized data, this stage segments objects in 2D images and projects them into 3D space using precise calibration data. This process adds critical depth and geometric context to visual detections, allowing the vehicle to understand not just what is present but also its exact location in the real world.
3. Multi-Modal Object Detection
Here, specialized models process both camera images and LiDAR point clouds simultaneously. Cameras provide rich semantic details (like distinguishing between a pedestrian and a cyclist), while LiDAR contributes accurate measurements of shape and distance. This parallel processing helps to create stronger, more reliable detections by leveraging the unique strengths of each sensor.
4. Tracking & Identity Management
As objects move across frames, tracking algorithms assign and maintain unique IDs. This continuity allows the system to recognize that the pedestrian seen in one frame is the same in the next, even if they are briefly hidden behind another object. This ensures a stable and consistent perception of dynamic elements in the environment.
5. Cross-Modal Fusion
This stage is where the results from vision and LiDAR are intelligently merged to build a single, unified model of the environment. This step reduces errors, improves coverage in tricky situations like occlusions, and ensures that detections are consistent and accurate across sensors.
6. Output Generation & Visualization
The final outputs of the pipeline are formatted for use by downstream AV systems for tasks like planning and control. At the same time, a visualization component is created to allow developers and engineers to inspect and validate the results. This visualization supports testing, debugging, and ensures the transparency needed to build public trust.
Illustrative Scenarios:
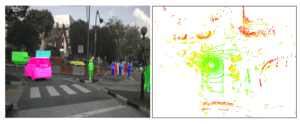

Advantages
The modular pipeline is highly effective for AV perception, delivering a solution that is not only robust and scalable but also more precise and transparent than traditional methods.
- Higher Precision: The pipeline’s data fusion and multi-modal detection stages work together to reduce noise and enhance accuracy, resulting in fewer false positives and more reliable object detection. This is critical for making safe, confident decisions.
- Improved Robustness: Engineered to handle real-world challenges, this pipeline stands out from systems that fail in unpredictable conditions. It seamlessly manages occlusions, mitigates the impact of sensor noise, and gracefully handles missing data, ensuring consistent performance in diverse and complex environments.
- Enhanced Scalability: Each stage of the pipeline can be upgraded independently– a powerful benefit of a modular design. For instance, a new model such as the DINOv3 can be seamlessly plugged in to improve performance without a full system overhaul.
- Greater Transparency: In a world where AV safety is paramount, transparency is non-negotiable. For regulators and safety auditors, this step-by-step visibility makes it easier to understand the system’s behavior, build trust, and gain confidence in its deployment at scale.
Evaluating the Results
To validate the real-world performance of the model, the system was tested against large-scale, multi-sensor driving datasets. The results demonstrate a strong balance between accuracy and reliability, providing a foundation for a safe and effective autonomous system.
The model achieves a relatively high Precision, crucial for minimizing false positives and avoiding reactions to non-existent threats. However, its Recall is in the medium range, highlighting the need for improvement in detection accuracy, especially in tough conditions like occlusions and bad weather. The F1 Score signifies a strong overall performance without sacrificing precision or recall for one another. Lastly, the low MOTA (Multi-Object Tracking Accuracy) indicates that stronger tracking algorithms are needed to reduce all tracking errors.
These results validate the pipeline’s effectiveness and demonstrate a balance between accuracy and reliability.
Why This Matters for the Future
The rapid growth of the AV market shows global momentum, but market size alone doesn’t guarantee success. Trust does. A modular, transparent, and multi-modal perception system is the foundation for building AVs that people will rely on daily.
This isn’t just about autonomy; it’s about designing systems that are accountable, adaptable, and safe at scale. As the industry races toward 2030, those qualities will decide which technologies move from prototypes to the streets.
Conclusion
The future of autonomous mobility depends on a vehicle’s ability to perceive the world with precision. Though the worldwide AV market is expanding quickly, trust is the ultimate measure of success.
The modular perception pipeline is the foundational solution. By organizing the complex task of object detection and localization into distinct, flexible stages, from synchronization to Cross-Modal Fusion, this architecture overcomes the limitations of traditional camera-first and LiDAR-first systems. This design delivers three critical advantages: Improved Robustness, Enhanced Scalability, and Greater Transparency for regulators and safety auditors to validate the system’s behavior.
At iMerit, these pipelines are powered by advanced annotation technology such as our 3D Point Cloud Tool (3D PCT), built to support multi-sensor fusion workflows with pixel-accurate labeling, automated pre-annotations, and seamless quality review loops. By combining expert-driven annotation with tools purpose-built for complex LiDAR and camera datasets, iMerit helps AV companies accelerate perception model training and validation with confidence.
Through this integrated approach, iMerit is driving the industry from prototypes to reliable deployment in the real world, designing AVs that are accountable, adaptable, and safe.