Fine-tuning a pre-trained 3D model is a crucial step in making LiDAR perception systems effective in the real world, particularly in complex, domain-specific environments such as off-road vehicles, agricultural robotics, or underground mining. While general-purpose models offer a strong starting point, they often underperform when faced with novel terrain, object types, or weather conditions.
In this blog, we’ll explore why fine-tuning these models matters, the practical challenges teams face, and the strategies that lead to more accurate and context-aware 3D perception.
What Is a Pre-trained 3D Model?
Pre-trained 3D models are perception models initially trained on large, general-purpose datasets, often representing urban or highway environments. These models learn to detect and classify objects using LiDAR data, sometimes fused with radar or camera inputs. Pre-trained models serve as a foundation, saving time and computing costs during development.
But their effectiveness diminishes when deployed in niche domains, like a vineyard, warehouse, or mining tunnel, where object types and point cloud characteristics vary widely.
At iMerit, we have seen how pre-trained models often falter in edge-case-heavy environments from mining shafts to greenhouse fields, and why targeted fine-tuning makes all the difference.
What Makes a Pre-trained 3D Model Adaptable?
The success of fine-tuning hinges on the foundation. A good pre-trained 3D model should offer:
- A well-architected model, typically trained on large-scale LiDAR datasets, offers a flexible foundation for fine-tuning.
- Modular design that allows replacing or updating parts of the pipeline (e.g., voxelization layer, detection head) without full retraining.
- Support for different point cloud densities and sensor types (spinning LiDAR, solid-state, stereo depth, radar).
Adaptable models make it easier to transfer learning to new domains. But to fine-tune them effectively, you need data that reflects your target use case, down to the level of label classes, environmental conditions, and object geometry.
Why Fine-Tuning Matters in Domain-Specific 3D Perception
Training a 3D model from scratch requires massive data and computing resources. Pre-trained models offer a valuable head start by providing already-learned 3D feature representations, but these models are typically trained on benchmark datasets like KITTI or Waymo Open, which are optimized for general urban driving scenes.
In real-world applications, the environment, sensor configuration, and object types can differ dramatically. A model trained to detect sedans on a highway might struggle with low-profile harvesters in a cornfield, forklifts in a warehouse, or mining trucks in dusty underground tunnels. This is where fine-tuning pre-trained 3D models for domain-specific LiDAR datasets becomes critical.
Key motivations for domain-specific fine-tuning include:
- Domain shift: Pre-trained models often fail to generalize to new sensor inputs, object types, and scene dynamics.
- Environmental diversity: Changing terrain, lighting, and weather conditions significantly affect LiDAR returns.
- Safety-critical use cases: Model accuracy directly impacts decision-making in AVs, drones, and industrial robots.
- Lower development costs: Fine-tuning reduces the need to build massive, fully custom datasets and avoids training models from scratch.
- Higher accuracy: Tailoring models to niche data improves performance on real-world tasks.
- Faster time to deployment: Leveraging existing weights cuts down development cycles.
Why Fine-Tuning Pre-Trained Models Fails Without the Right Data and Annotation Tools
Many teams assume a strong base model is enough, but without adaptation to the domain’s visual and structural nuances, performance flatlines. Context-specific data and precise labeling remain critical.
Common barriers to effective fine-tuning:
- Insufficient annotated domain data: Many models are fine-tuned on a small number of labeled examples, often curated manually. This results in inconsistent performance, especially in edge cases.
- Inadequate annotation tooling: Tools not optimized for 3D point cloud labeling, especially ones lacking multi-sensor fusion capabilities, make it difficult to generate high-quality training data.
- Lack of expert QA and feedback loops: Annotated data must reflect real-world conditions. Without human-in-the-loop QA workflows and tight feedback cycles, model predictions can drift quickly.
- Limited support for custom taxonomies: Domains like agriculture, construction, or indoor robotics need label taxonomies beyond vehicles and pedestrians. Many platforms aren’t built to handle this complexity.
These issues limit model generalization and result in poor downstream performance when moving from highway to vineyard or factory floor.
Strategies to Fine-Tune Pre-trained 3D Models Effectively
Fine-tuning pre-trained 3D models for domain-specific LiDAR datasets can significantly improve accuracy and real-world outcomes— but only when supported by tailored data pipelines, annotation platforms, and validation processes. Many teams underestimate the complexity of adapting a model to new conditions. You can have the right architecture and a powerful base model, but without domain-specific training data and the right annotation workflows, performance plateaus.
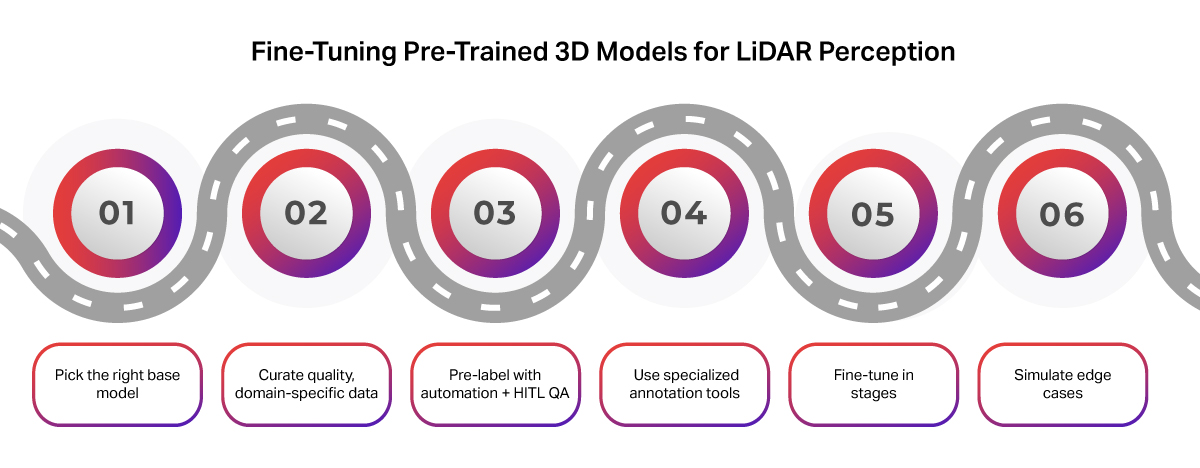
Here’s a practical guide to getting it right:
1. Choose a Suitable Base Model
Start with a modular architecture that aligns with your target application. For example:
- PointPillars or SECOND: Optimized for real-time inference.
- PV-RCNN or CenterPoint: Ideal for high-accuracy needs in dense or cluttered environments.
A good pre-trained 3D model should also have:
- Strong backbone architecture (e.g., PointNet++, SECOND, PV-RCNN) trained on large-scale LiDAR datasets like nuScenes or Waymo Open Dataset.
- Look for a modular model structure that supports targeted upgrades like replacing the detection head or sensor input, without starting from scratch.
- Support for different point cloud densities and sensor types (spinning LiDAR, solid-state, stereo depth, radar).
- Compatibility with your target input structure, whether it’s LiDAR-only, LiDAR+camera, or LiDAR+radar.
This flexibility accelerates adaptation to domain-specific environments, but only if your training data matches the target use case across label classes, environmental conditions, and sensor setups.
2. Curate High-Quality, Domain-Specific Data
Data quality and relevance matter more than volume. Ensure your dataset includes:
- Real-world scenarios from your target environment
- Diverse object classes, terrain, and weather conditions
- Sensor metadata (LiDAR type, mounting angle, calibration sync)
Common challenges to effective fine-tuning include:
- Sparse and noisy data: LiDAR point clouds can be sparse, especially for small or distant objects. Environmental noise (rain, fog, reflective surfaces) further degrades signal quality.
- Lack of domain-specific datasets: Most teams lack high-quality annotated data for niche scenarios like off-road terrain, warehouse automation, or agricultural robotics.
Where possible, collect LiDAR sequences that capture rare, risky, or safety-critical edge cases. Multi-sensor synchronization across modalities is also key for certain deployments.
3. Automate Pre-Labeling, But Use Human-in-the-Loop QA
Accelerate labeling by combining automation with expert review:
- Pre-label with a weak model or heuristic
- Refine with trained annotators
- Apply senior review for edge cases and consistency
iMerit integrates pre-labeling and human-in-the-loop QA within a scalable pipeline to ensure precise annotations, even for occluded or partially visible objects. Use model-in-the-loop workflows to guide re-labeling and continuously improve training datasets.
4. Use the Right Annotation Tooling
Your tooling must support the complexity of 3D data. Look for:
- 3D cuboids, segmentation masks, and per-point labeling
- Multi-sensor fusion across LiDAR, radar, and cameras
- Temporal consistency and frame tracking
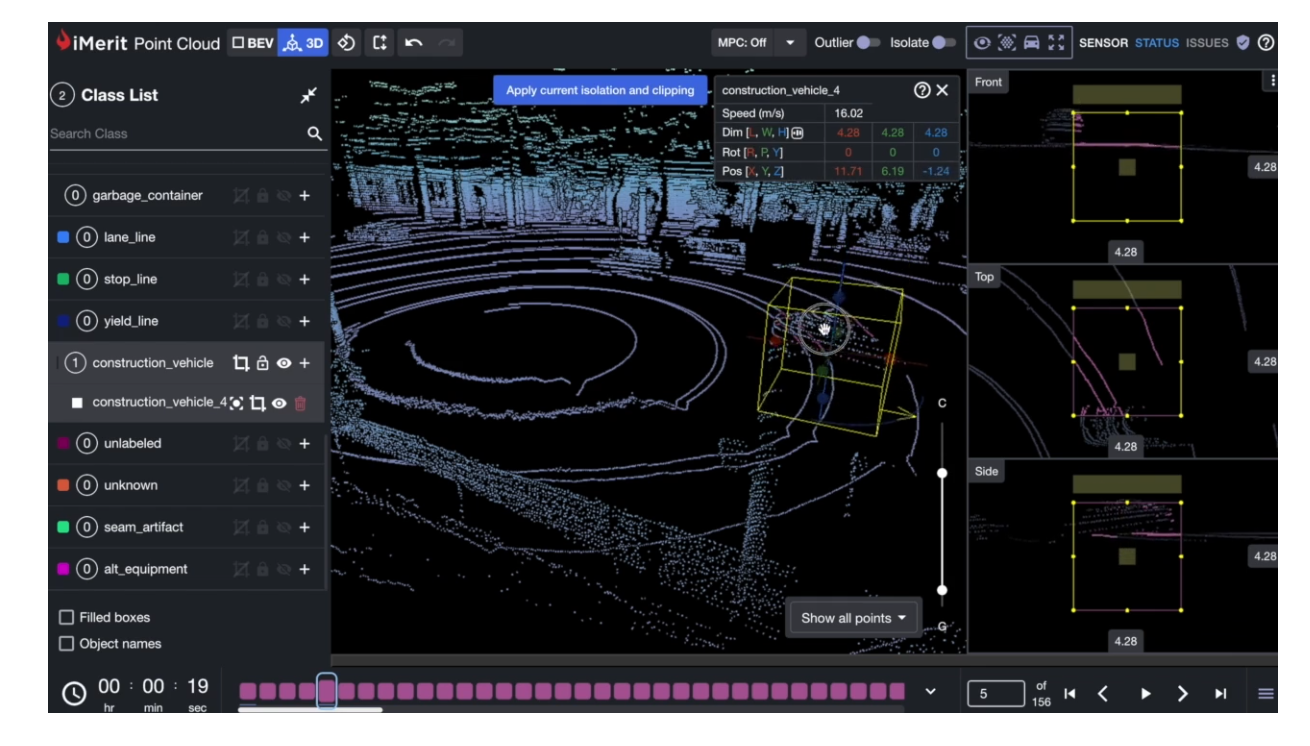
iMerit’s 3D Point Cloud Tool and Ango Hub enable dynamic, collaborative workflows with tight MLOps integration.
Tooling limitations can block progress. Many platforms fall short when it comes to multi-sensor fusion, time-series annotation, or per-point classification features. Labeling 3D point clouds is also time-consuming and cognitively demanding. Annotators must handle partial objects, occlusions, and 3D spatial reasoning.
5. Fine-Tune Progressively, Not All at Once
Avoid overfitting by tuning in phases:
- Freeze backbone layers early on
- Fine-tune task-specific heads with caution
- Monitor class-wise and region-specific metrics (e.g., near vs. far objects)
Add robustness using domain-specific augmentations, like occlusion simulation, point dropout, or rotation, to mimic deployment conditions. Iterative fine-tuning, guided by QA loops, helps the model generalize to edge cases and environmental variations.
6. Leverage Simulation for Rare Scenarios
Synthetic point clouds can help you:
- Fill gaps in rare or risky edge cases
- Expand your dataset for objects like tree stumps, ditches, or pipes in agricultural fields
- Simulate occlusion and lighting challenges
Simulation also offers a controlled way to test model robustness before real-world deployment.
iMerit’s Approach: Expert-Led Fine-Tuning with Platform Support
At iMerit, we support every stage of this fine-tuning lifecycle:
- Our 3D Point Cloud Tool enables labeling with cuboids, segmentation masks, per-point classification, and frame tracking.
- Ango Hub, our secure data annotation platform, integrates ML pipelines, handles model label ingestion, and runs custom QA workflows.
- We offer multi-sensor fusion annotation for LiDAR, radar, RGB, and stereo depth, critical for real-world robotics and autonomous perception.
- Human-in-the-loop teams bring domain knowledge in agriculture, mobility, and industrial robotics to deliver consistently high-quality training data.
Human-in-the-loop QA workflows like those used in iMerit’s LiDAR annotation pipeline ensure label consistency even in complex, low-visibility environments.
Annotation Quality: The Backbone of Fine-Tuning Success
Even the best model architecture can’t overcome bad data. Poorly labeled point clouds lead to:
- Unstable model predictions
- Confused object boundaries
- False confidence in metrics
Consistent, high-quality labels with human-in-the-loop validation ensure your model learns the right patterns. iMerit’s annotation operations are optimized for accuracy, precision, and scale, especially for LiDAR-based applications.
Conclusion: Build Better with the Right Data and Tools
Fine-tuning a pre-trained 3D model is a powerful shortcut to production-ready perception systems. But your results depend heavily on the quality of your data and annotations.
iMerit offers both a robust 3D Point Cloud Tool and expert-led annotation teams that understand the edge cases, environments, and geometry your model needs to master.
Ready to fine-tune with confidence? Talk to our experts.
Quick FAQ: Fine-Tuning LiDAR Models
Q: How do I tell if a pre-trained model suits my domain?
A: Check its original training data (urban, indoor, off-road), supported sensors, and how easily components like the detection head can be swapped.
Q: Is it better to collect more data or improve the quality of what I have?
A: Quality matters more. A small, well-annotated dataset, especially with edge cases, beats thousands of noisy frames.
Q: What’s the biggest mistake teams make when fine-tuning?
A: Relying on a base model alone. Without domain-specific labels, expert QA, and the right tools, results often stagnate.