iMerit’s end-to-end data labeling services paired with its 5,500 full-time data annotation experts deliver high-quality training data that fuels the machine learning models created by engineering, product and data science teams from leading autonomous mobility enterprises.
Autonomous Mobility
iMerit is a leading global technology services company providing high quality data annotation across computer vision, natural language processing and content services that powers machine learning and artificial intelligence applications for large enterprises across the autonomous transportation sector.
Services

Multi-sensor Fusion
Combining LiDAR and images from multiple angles captured from different sensors, iMerit’s teams help to reduce uncertainty in navigation.

PanOptic Segmentation
Coupling instance and semantic segmentation, iMerit enrichment teams identify the pixels in images as belonging to a class and identify what instances of that class they belong to.

LiDAR
iMerit teams label images and videos in 360 degree visibility, captured by multi-sensor cameras, in order to build accurate, high-quality, ground truth datasets to power autonomous driving algorithms.
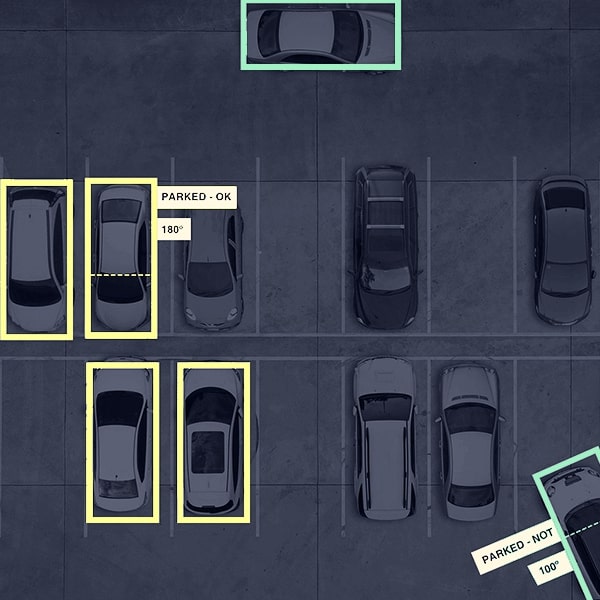
Bounding boxes
iMerit Computer Vision experts use rectangular box annotation to illustrate objects and train data, enabling algorithms to identify and localize objects during ML processes.

Polygon Annotation
Expert annotators plot points on each vertex of the target object. Polygon annotation allows all of the object’s exact edges to be annotated, regardless of shape.

Semantic Segmentation
Images are segmented into component parts, by the iMerit team, and then annotated. iMerit Computer Vision experts detect desired objects within images at the pixel level.
Object tracking
iMerit teams detect instances of semantic objects of a certain class in digital images and videos, use cases could include face detection and pedestrian detection.
In-cabin Monitoring
Data Annotation Technology & Automation for Driver and Occupant Monitoring Systems
Built on the Ango Hub platform, iMerit’s in-cabin sensing data labeling solution includes predictive AI models for automation and active human oversight. The platform offers pre-trained models for automatic facial point detection and other key characteristics identification.

"iMerit's incredibly knowledgeable data labelers are part of our team and are the right people for our enrichment efforts."
Director of Data Products, Research Institute of Autonomous Driving

Solutions
By the Numbers
5500
Full-time, in-house data annotation experts employed by iMerit
250
Mn
Data points enriched for AV use cases
60
%
Of the top autonomous vehicle players partner with iMerit

Certification Obtained
The Trusted Information Security Assessment Exchange (TISAX) is an internationally acknowledged certification standard within the automotive sector, evaluating an organization’s IT infrastructure, processes, and systems for security. iMerit regularly undergoes TISAX assessments and audits to guarantee adherence to the set security standards. iMerit adopts a methodical strategy for managing information security to uphold the utmost levels of confidentiality, integrity, and accessibility of sensitive data. This encompasses the implementation of strong security policies and the consistent conduct of risk assessments.
Featured
Content

Working with global AI leaders











Getting
Started!
The need for speed in high-quality data annotation has never been greater. iMerit combines the best of predictive and automated annotation technology with world-class data annotation and subject matter experts to deliver the data you need to get to production, fast.
Let's Connect