Reinforcement Learning (RL) has made notable advances in recent years. It is powering systems that can play complex games, control robots, and optimize large-scale operations. But RL still faces a major challenge: reasoning. Many reinforcement learning models struggle when required to follow multi-step logic or solve problems that extend beyond simple trial-and-error.
RL depends on more than just large amounts of data. The quality of reasoning within that data often decides how well an RL agent can learn to make decisions, adapt to new tasks, and avoid errors. When datasets are not carefully reviewed, models may pick up flawed logic or shortcuts that compromise their reliability.

Expert-vetted reasoning datasets address this problem by providing structured, domain-aware training material. They capture the reasoning steps leading to outcomes, enabling agents to understand why certain actions work better than others.
Let’s explore why expert-vetted reasoning data matters and how it improves RL performance.
Raw Data is Holding Back Your RL Agent: Here’s Why
Reinforcement Learning agents depend heavily on the quality of the signals they receive during training. If the reinforcement learning training data is weak, the agent often learns the wrong patterns. Raw or unfiltered reasoning data usually has four main issues:
- Errors in Reasoning Paths: Many datasets contain incorrect steps or missing logic. When an RL model learns from these traces, it copies the same mistakes.
- Noise and Inconsistency: In open datasets, the same task might be solved in many different ways, some good and some poor. This inconsistency makes it more difficult for the agent to determine which strategy is most effective.
- Overfitting: Non-vetted data may teach an agent to rely on patterns that look correct in training but fail in real-world environments. This problem frequently occurs in robotics, where minor errors in reasoning traces can result in failed actions or safety issues.
- Bias and Oversimplification: Raw data often reflect easy cases or common heuristics. RL agents trained on such data fail to generalize to more complicated and complex problems.
These issues cause unstable training and weaker performance in real-world environments. For RL systems to reach reliable reasoning, the data they learn from must be consistent and carefully structured.
The Role of Reasoning in Reinforcement Learning Models
Reinforcement learning agents learn by interacting with an environment and receiving rewards or penalties. In many cases, this training is enough to optimize actions, but it does not guarantee sound reasoning. Without reasoning data, an agent may rely on trial and error instead of understanding the logic behind a decision.
Reasoning datasets address this gap. They include step-by-step explanations, structured decision paths, and logical chains that show how they reach a certain outcome. For example, in robotic manipulation, a reasoning dataset for reinforcement learning might include:
- The block is red, so select the red object.
- Move the gripper 10 cm left to align with the block.
- Close the gripper only when sensors confirm contact.
- Lift vertically to avoid collisions.
This structured reasoning shows the logic behind each movement rather than just recording that the robot successfully picked up the block.
In traditional RL, the agent only receives a scalar reward from the environment. In reasoning-augmented RL, there is often an additional reward model or critic trained on expert-vetted reasoning data. This model evaluates not just the outcome but also the quality of the reasoning trace that led to it. The agent, therefore, learns policies that optimize for both task success and logical coherence.
This workflow differs from standard RL by incorporating an extra feedback channel and reasoning quality into the reward signal. As a result, models move from simple behavior imitation to understanding the reasoning behind effective actions. This makes them more reliable in new or unseen situations.
What is Expert-Vetted Data & Why It Matters for Reinforcement Learning
Expert-vetted data refers to datasets that are curated, annotated, and validated by domain specialists. Unlike raw or crowdsourced datasets, expert-reviewed collections ensure logical rigor and consistency in reasoning paths. For RL, this means training signals that better reflect real-world decision processes.
Each example in such a dataset for reinforcement learning usually contains:
- A clear problem statement so the agent knows what it is solving.
- Step-by-step reasoning showing how to reach the solution, not just the final answer.
- Validation by experts to ensure that every step is correct and consistent.
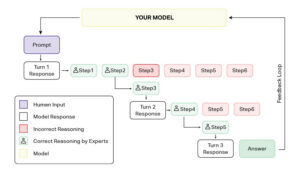
Training on these expert-reviewed traces enables RL agents to build more stable policies and generalize better when facing new problems.
Here is why expert-vetted data matters:
- Better Reward Modeling: With correct reasoning steps, the reward function can be shaped around valid logic rather than just outcomes. This helps the agent understand why a solution works. For example, OpenAI’s RLHF pipeline relies on preference data. However, performance improves significantly when annotation guidelines are enforced by experts instead of broad crowd groups.
- Reduced Noise: Faulty or inconsistent reasoning examples may cause agents to rely on shortcuts or spurious correlations. Expert curation removes these errors and reduces variance in policy learning to make training more stable and predictable.
- Guided Exploration: In complex environments, unguided exploration often wastes time and resources. Expert reasoning offers structured pathways, like curriculum learning, where agents master simpler subtasks before tackling harder reasoning chains.
- Improved Generalization: When the agent is exposed to high-quality reasoning structures, it can apply those patterns to new and unseen problems.
iMerit’s Deep Reasoning Lab and Scholars Program embed expert oversight into production workflows. Their teams create reasoning-rich datasets for reinforcement learning from human feedback, chain-of-thought supervision, and alignment tasks. With expert judgment and secure annotation pipelines, iMerit enables large-scale model correction and safer deployment of reinforcement learning models in real-world use.
Evidence and Case Studies
Research in AI has already shown clear gains when expert-reviewed reasoning data is used in training.
Mathematics and Logic Tasks
Studies with large language models have shown that models trained on curated, step-by-step math solutions make fewer logical errors and achieve higher accuracy compared to models trained on raw or crowd-sourced data.
The Big-Math dataset offers a compelling example. It contains over 250,000 high-quality, manually verified math problems, built specifically for RL training. Its design balances quantity with accuracy and provides diverse and verifiable problems that help reasoning-focused models learn more reliably than datasets that sacrifice one over the other.
One foundation model team partnered with expert mathematicians from iMerit’s Scholars program to stress-test reasoning reliability. Over 60 specialists created 600 original math prompts with chain-of-thought reasoning traces, capturing not only the problem and solution but also step-by-step logic, model failures, and expert corrections.
Delivered in two weeks, this dataset provided structured, expert-reviewed traces that exposed reasoning flaws and supplied precise signals for reinforcement learning tuning.
Code Generation
RL agents trained with expert-reviewed coding traces learn better debugging strategies. Instead of guessing fixes, they follow structured reasoning to locate and resolve errors. This leads to more reliable code output.
A recent study on reasoning-driven program repair showed that models trained with structured, expert-validated traces achieved higher accuracy on real-world debugging tasks compared to baseline RL-trained agents. These models followed logical problem decomposition rather than random trial-and-error fixes, producing safer and more reliable code.
Autonomous Systems
In robotics and autonomous driving, reasoning errors can lead to unsafe or inefficient actions. RL agents trained with expert-vetted decision sequences learn structured planning strategies, such as obstacle avoidance, collision-free pathfinding, and traffic-aware navigation.
For example, in simulation environments, expert-designed reasoning traces may include explicit rules like “yield before entering intersections” or “prioritize pedestrians over vehicles.” These step-by-step sequences go beyond raw outcomes by encoding the logic behind safe movement.
In the LiDAR & 3D Point Cloud Annotation case study, iMerit worked with an autonomous vehicle company to label targets (cars, pedestrians, barriers) and delineate road boundaries, crosswalks, and traffic signs across both 2D camera images and 3D LiDAR point clouds. They used curated guidelines, expert annotators, and human-in-the-loop validation to produce datasets that support accurate scene perception and object detection.
Quantitative Gains
Expert-vetted reasoning datasets deliver measurable improvements in reinforcement learning. Models trained on these datasets converge faster because structured reasoning traces reduce noise and guide learning toward stable policies.
They also enhance accuracy by helping agents avoid faulty shortcuts and adopt the correct logic behind each decision. With illogical or unsupported inferences minimized, hallucinations decrease. This makes models more reliable in sensitive fields such as healthcare, finance, and coding.
Building and Maintaining Expert-Vetted Datasets
Creating high-quality reasoning datasets requires careful curation and ongoing validation.
1. Methods for Dataset Curation
Expert annotation is key, with domain specialists reviewing, correcting, and organizing data to maintain logical consistency. Hybrid approaches combine human expertise with AI-assisted tools that flag inconsistencies or errors and speed up the review process while maintaining accuracy.
2. Continuous Improvement through Feedback Loops
Expert-vetted datasets are not static. Continuous feedback from model outputs and downstream tasks helps identify areas for improvement or gaps. Data is regularly tested in real-world or simulated environments, and insights from model performance are used to refine reasoning traces. This ensures that datasets evolve alongside model needs and emerging scenarios.
3. Collaborations Between AI Researchers and Domain Experts
Collaboration between AI researchers and domain experts further strengthens the datasets. Researchers define the model requirements and evaluation metrics, while experts contribute contextual knowledge and validate reasoning paths.
iMerit operationalizes these best practices through its Scholars and Ango Hub programs. Scholars contribute domain-specific knowledge to annotate complex reasoning data, while Ango Hub manages secure, scalable workflows for hybrid human-AI vetting. This combination ensures datasets are continuously refined and aligned with real-world applications in robotics, healthcare, and autonomous systems.
Evaluation and Benchmarking
Evaluating reasoning datasets requires more than accuracy checks. The key is to measure whether reasoning traces actually improve model behavior. Standard benchmarks like MMLU or GSM8K test factual recall and problem-solving, but they often fail to capture the quality of step-by-step reasoning.
For reinforcement learning, evaluation must include:
- Trace Consistency: Verifying that each reasoning step follows logically without contradictions.
- Reward Alignment: Measuring whether the reasoning paths generate stable and meaningful rewards for policy optimization.
- Error Propagation: Tracking how small annotation errors affect downstream actions during training.
- Generalization Metrics: Testing the model on out-of-distribution tasks to see if reasoning skills transfer.
Human-in-the-loop review is often combined with automated checks. For example, language models can flag reasoning inconsistencies, but expert annotators confirm validity. This hybrid approach increases dataset reliability without slowing down pipeline throughput.
Benchmarking also requires creating domain-specific test sets. For instance, a reasoning dataset for medical AI must be validated against clinical logic, not just general benchmarks. Without this, reinforcement models may show high test scores yet fail in deployment.
Practical Applications of Domain Vetted Reasoning
Expert-vetted reasoning datasets are essential in domains where accurate decision-making and logical rigor directly impact outcomes.
1. Scientific Discovery
In biology and chemistry, RL models trained on expert-reviewed experimental sequences can predict reaction outcomes, optimize lab processes, and propose novel compounds. These models reduce the risk of infeasible or unsafe predictions by learning from verified reasoning steps rather than raw experimental data.
2. Financial Decision-Making
Trading algorithms and risk assessment models benefit from reasoning-verified datasets. Expert annotations help RL agents understand causal relationships between market events, regulatory constraints, and investment strategies. This leads to more robust decision-making and minimizes costly errors.
3. Safety-Critical Systems
In healthcare or cybersecurity, reasoning errors can have severe consequences. RL agents trained on expert-reviewed scenarios, such as treatment protocols or threat response sequences, learn explainable policies that prioritize safety while adapting to complex or dynamic environments.
Future of Reinforcement Learning with Vetted Reasoning Data
Expert-vetted reasoning datasets are shaping the next generation of reinforcement learning models.
- AI-Assisted Quality Control: AI tools can pre-screen new data for logical consistency and flag anomalies before human review. This hybrid approach accelerates dataset curation while maintaining high accuracy, ensuring RL models learn from reliable reasoning patterns.
- Integration with Large Language Models: LLMs can guide RL agents through structured reasoning tasks and provide intermediate steps or chain-of-thought suggestions. When combined with expert-vetted data, this integration improves model interpretability and decision-making across complex domains.
- Building Reasoning Benchmarks: Expert-curated datasets allow researchers to create standardized benchmarks that evaluate reasoning capabilities rather than just task performance. These benchmarks help track improvements in multi-step planning, causal inference, and decision logic.
- Universal Reasoning Datasets Across Industries: With systematic vetting and cross-domain collaboration, it is possible to build universal reasoning datasets applicable to multiple industries. Such datasets can accelerate model training in domains like healthcare, finance, robotics, and scientific research, reducing redundant effort and improving model robustness.
Conclusion
Expert-vetted reasoning datasets are essential for improving reinforcement learning performance. They provide structured and domain-aware reasoning traces that help models learn not just actions, but the logic behind them.
Organizations that invest in high-quality reasoning data can train RL models that are more reliable, interpretable, and aligned with real-world requirements.
Integrating domain-expert workflows such as iMerit’s Deep Reasoning Lab and Scholars program transforms high-quality reasoning data into measurable performance gains. These programs combine expert annotation, hybrid human-AI vetting, and continuous dataset refinement to support safer and more accurate RL training.
For organizations aiming to scale RL solutions with precision and reliability, iMerit’s Deep Reasoning Lab and Scholars program provide a proven path to improve model performance through expert-curated reasoning datasets.
Work with iMerit’s Scholars and domain experts to build reasoning data pipelines that drive safer and more reliable AI!