Generative AI is revolutionizing software development, making it possible for large language models (LLMs) to convert natural language prompts, like “Write a Python function to sort a list,” into executable code. This exciting capability, called text-to-code, is reshaping how developers write, maintain, and scale software.
However, raw pretrained models often struggle to fully understand programming logic, developer intent, and context, which are critical for generating correct, reliable, and efficient code in real-world environments.
This is where Supervised Fine-Tuning (SFT) comes in — a crucial step that refines pre-trained models by training them on carefully curated, human-annotated examples tailored to coding tasks. iMerit delivers the high-quality data that powers this fine-tuning process, helping organizations build AI that doesn’t just generate code but writes code developers can trust.
What is Supervised Fine-Tuning (SFT)
AI models like Codex, CodeBERT, and Code Llama start as large pretrained models trained on massive datasets from the web and open-source repositories. But these models still lack the precision and domain knowledge necessary for consistent, production-ready code generation.
Supervised Fine-Tuning (SFT) is the process of taking a pretrained large language model and further training it on task-specific, labeled examples. In the context of coding, this means feeding the model high-quality pairs of natural language prompts and their corresponding code solutions. SFT enables the model to:
- Understand programming logic and code structure, learning how different constructs fit together logically.
- Align outputs with developer intent, ensuring the generated code matches what the user wants.
- Learn domain-specific conventions and syntax, adapting to particular programming languages, frameworks, or industries.
SFT is especially essential in coding because programming demands exactness; a misplaced bracket, incorrect indentation, or logic flaw can cause a program to fail. Only through supervised learning on high-quality, human-annotated data can models reliably produce syntactically correct and executable code that works in real-world scenarios.
Why Supervised Fine-Tuning Matters for Text-to-Code
Generating code is fundamentally different from many natural language tasks because even small errors, like a misplaced bracket or a logic flaw, can cause programs to malfunction, fail to compile, or introduce security vulnerabilities. While pretrained language models can generate code that appears plausible, they often miss critical details necessary for correctness, efficiency, and safety.
Supervised Fine-Tuning (SFT) addresses these challenges by training models on carefully curated and annotated examples that emphasize:
- Correct coding practices and syntactically valid code that compiles and runs.
- Context-aware generation that accounts for prior code, developer intent, project structure, and framework-specific conventions, ensuring new code integrates seamlessly into existing systems.
- Accurate interpretation of developer instructions, even for complex, multi-step programming tasks.
- Adaptability to various programming languages, frameworks, and domain-specific conventions.
- Reduction of bugs and vulnerabilities by incorporating secure coding patterns and error handling.
This targeted learning process ensures the model goes beyond superficial code generation, producing reliable, functional, and secure outputs that developers can confidently integrate into real-world applications.
The Role of High-Quality Data in SFT for Coding
The success of Supervised Fine-Tuning depends heavily on the quality, balance, and contextual depth of the dataset. In text-to-code applications, training data must go beyond basic instruction-code pairs to capture real-world programming dynamics. Effective SFT datasets should include:
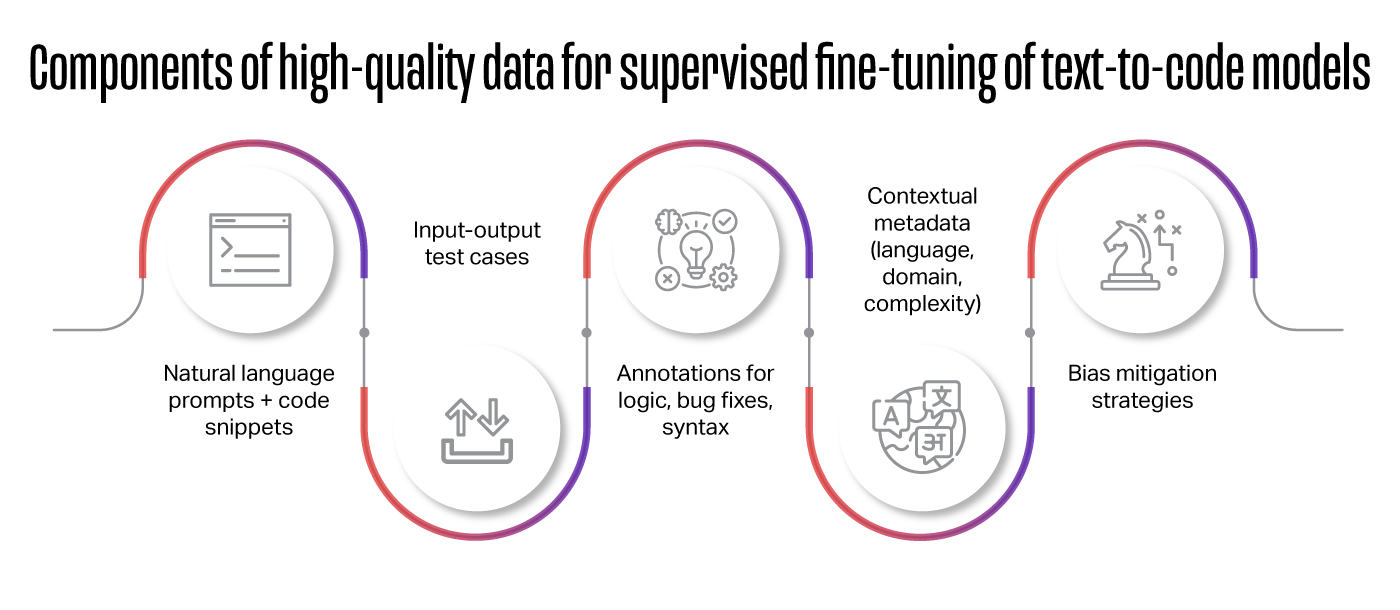
- Natural language prompts paired with correct code snippets ensure the model understands how instructions translate to code.
- Input-output test cases validating functionality, helping models learn correct behaviors beyond syntax.
- Annotations highlighting logic, bug fixes, and syntax correctness guide the model on nuances of code quality and correctness.
- Contextual information, such as preceding or surrounding code blocks, module intent, or architectural constraints, helps the model generate code that fits the broader environment, not just isolated logic.
- Bias mitigation strategies to ensure diverse representation of programming styles, languages, and domains, reducing overfitting and improving generalization to unseen scenarios.
- Metadata tagging for language, domain, task type, and complexity level, enabling fine-grained control and better specialization during training.
iMerit excels at producing high-quality, annotated datasets by leveraging annotators with coding expertise who:
- Label code functionality and logic flow.
- Identify and correct syntax or logical errors.
- Tailor datasets to industry-specific applications.
- Conduct rigorous multi-stage quality control.
By combining human-in-the-loop validation with scalable infrastructure, iMerit ensures data is precise, consistent, and production-ready, forming the foundation for trustworthy text-to-code AI.
The SFT Workflow for Text-to-Code Models
The supervised fine-tuning pipeline consists of several detailed stages, each supported by iMerit’s expert teams to ensure high-quality outputs:
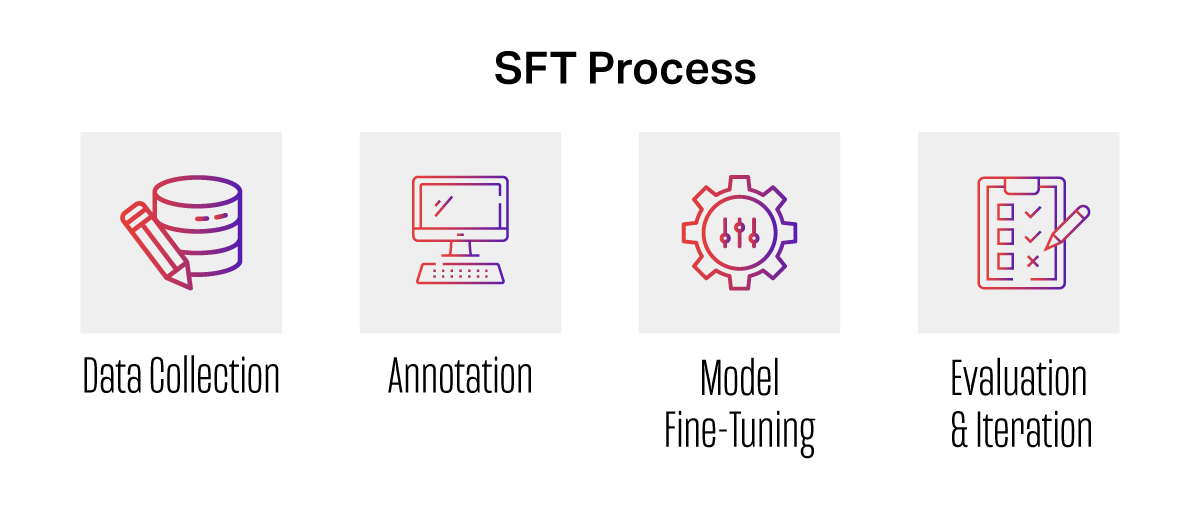
- Data Collection
Gather diverse prompts and corresponding code across multiple programming languages (e.g., Python, JavaScript, SQL). Ensure dataset coverage for various domains, complexity levels, and edge cases to build model robustness. - Annotation
Label prompts for intent (e.g., interpreting “sort a list” as a sorting algorithm request). Verify code syntax and functionality, annotating errors, inefficiencies, or potential bugs. Add metadata to provide context such as programming language, frameworks used (e.g., Flask), and domain specifics. - Model Fine-Tuning
Use the annotated dataset to fine-tune pretrained large language models (e.g., CodeBERT, Codex) via supervised learning. Optimize hyperparameters like learning rate and batch size to minimize loss and maximize performance on task-specific datasets. - Evaluation & Iteration
Assess model performance using metrics such as code accuracy, BLEU score, and functional correctness (e.g., passing automated test cases). Identify gaps in dataset coverage or annotation quality, focusing on underrepresented prompt types or edge cases. Refine annotations and expand datasets accordingly to close gaps.
Challenges in SFT for Text-to-Code Models
While SFT empowers code generation models with greater accuracy and reliability, it brings a combination of business and technical challenges that must be carefully addressed.
| Operational Challenges | Technical Challenges |
|---|---|
| Data Complexity: Programming languages have strict syntax rules, complex semantics, and diverse frameworks, making annotation more demanding than natural language tasks. | Instruction-Code Pair Ambiguity: Natural language instructions often lack clarity or specificity, making the target code open to interpretation. |
| Scale and Diversity: Collecting and annotating sufficiently large and varied datasets to cover multiple languages, domains, and edge cases requires extensive resources. | Semantic Alignment of Instruction Granularity: Instructions can be overly broad or overly detailed; aligning the model’s output scope to the intended granularity remains difficult. |
| Quality Assurance: Ensuring annotation consistency, logic accuracy, and alignment with developer intent requires multiple validation layers and expert reviewers. | Over-Compression in Autoregressive Learning: Compressing complex logic into linear token sequences causes the model to lose nuanced control flows and abstractions. |
| Security and Privacy: Handling proprietary or sensitive codebases demands rigorous data governance and compliance controls. | Syntax is Cheap, Semantics are Expensive: Generating syntactically valid code is relatively easy; ensuring it behaves as intended (semantics) under execution is far more difficult. |
| Data Scarcity: High-quality annotated code datasets are limited, especially in niche or domain-specific contexts. | Prompt Sensitivity & Tokenization Drift: Small variations in prompts or token boundaries can lead to wildly different outputs, especially for low-resource or edge-case instructions. |
| Complexity of Annotations: Understanding developer intent and functional correctness requires deep programming expertise. | Loss Spikes from Long-Sequence Position Bias: Transformer-based models often struggle with token accuracy at longer positions, causing erratic training loss behavior. |
| Evolving Languages: Codebases and syntax evolve, requiring continuous dataset updates. | Model Evaluation: Measuring the quality of generated code is complex, often requiring functional testing beyond syntactic correctness. |
| Bias and Overfitting: Overrepresentation of certain styles or domains can lead to biased model behavior. | Post-SFT Model Fragility in IDEs: Even well-fine-tuned models may behave unpredictably in real-time environments, where partial context and rapid feedback loops are involved. |
| Tooling and Automation Limitations: Current annotation tools often lack semantic code understanding or auto-validation. Scaling requires smarter platforms and AI-assisted tools to enhance quality and ease manual workload. | Limited Generalization: Even after fine-tuning, models often struggle with novel or creative coding tasks that fall outside their training patterns, reducing reliability in real-world, open-ended scenarios. |
iMerit mitigates these challenges through domain-specific annotation teams, adaptive workflows, operational scalability, and iterative feedback loops.
How iMerit Powers SFT for Coding Models
iMerit plays a crucial role in delivering the high-quality, domain-specific data essential for effective supervised fine-tuning of coding models. iMerit’s approach combines deep technical expertise, rigorous quality assurance, and scalable workflows to support AI teams in building reliable, production-ready solutions.
- Expert Annotators: iMerit’s team includes annotators fluent in multiple programming languages such as Python, JavaScript, SQL, and others, who understand coding logic, frameworks, and best practices.
- Custom QA Pipelines: We implement tailored quality assurance processes that verify not just syntax correctness but also logic accuracy and alignment with developer intent, ensuring every data point contributes to model precision.
- Flexible and Scalable Workflows: iMerit’s workflows adapt seamlessly across different languages, domains, and annotation styles, allowing clients to scale their projects without compromising data quality.
- Robust Data Security: We uphold strict data security and compliance standards, meeting enterprise requirements to protect sensitive codebases and intellectual property throughout the annotation lifecycle.
By combining human expertise with cutting-edge technology, iMerit ensures the supervised fine-tuning pipeline is powered by clean, precise, and context-rich datasets. This foundation helps AI models not only generate syntactically correct code but also produce developer-trusted, executable solutions that can scale with real-world demands.
Real-World Applications of SFT in Coding
SFT-powered text-to-code models are transforming software development workflows. Key applications include:
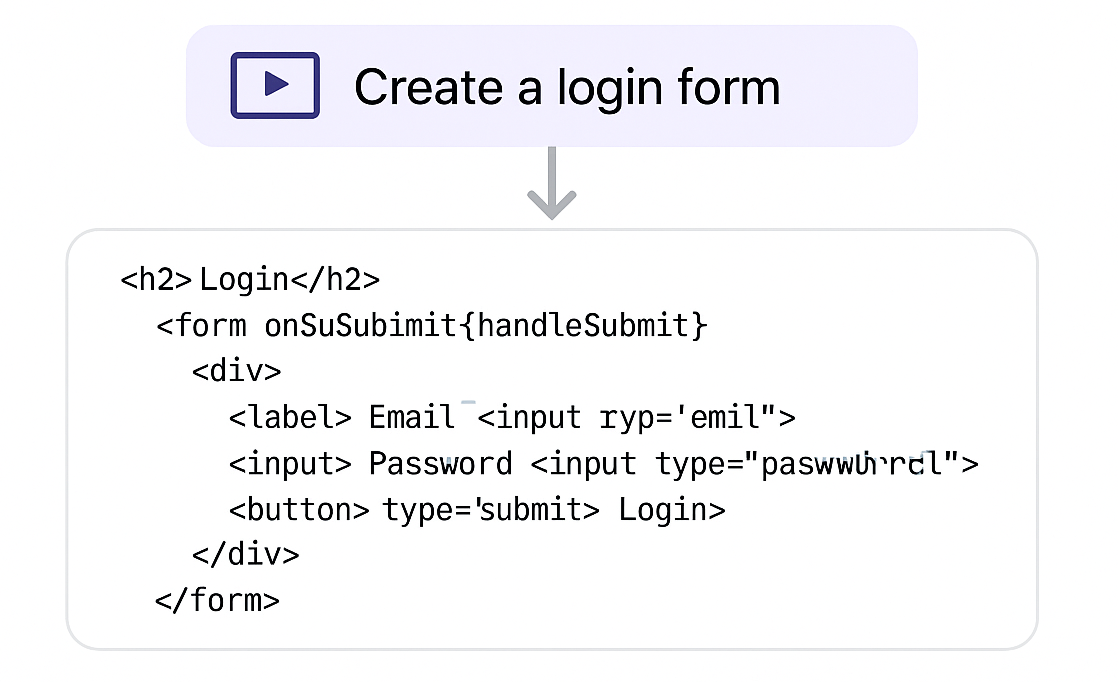
Automated Code Generation
Generating boilerplate code for web frameworks (e.g., React components from prompts like “Create a login form”).
Developer Assistance
Powering IDE plugins such as GitHub Copilot, offering real-time code suggestions based on natural language or partial code.
Low-Code/No-Code Platforms
Enabling non-programmers to build applications by describing functionality in plain English, with models generating the code.
For example, a client building an AI-powered IDE might partner with iMerit to create a dataset of JavaScript code-text pairs, annotated for ES6 syntax and React-specific patterns. iMerit’s annotators would verify code functionality, label edge cases (e.g., async/await errors), and ensure the dataset covers diverse use cases, resulting in a model that delivers accurate, context-aware suggestions.
Conclusion
Supervised Fine-Tuning is the cornerstone for transforming pre-trained language models into reliable, developer-trusted coding assistants. The quality and specificity of annotated data directly impact a model’s ability to generate executable, accurate, and secure code.
iMerit empowers AI teams by delivering high-quality, expertly curated datasets tailored for text-to-code fine-tuning. Skilled annotators, custom QA processes, and flexible workflows powered by the Ango Hub platform ensure your models perform with precision across languages and domains, accelerating innovation and reducing time to market. Through intelligent automation, streamlined task management, and integrated quality controls, Ango Hub accelerates annotation at scale while maintaining consistency and accuracy.
Connect with iMerit to harness the full potential of AI-driven software development—building the future of coding, one line at a time.