IMAGE GENERATION EVALUATION
TRUST THROUGH PRECISION HUMAN EVALUATION
Human evaluation ensures that AI-generated images are safe, accurate, on-brand, legally compliant, and visually high-quality.

MULTIMODAL IMAGE EVALUATION
BUILT FOR FRONTIER MODELS AND AI SYSTEMS
iMerit delivers multimodal image evaluation for frontier generation systems using calibrated human review, custom rubrics, and domain specialists. Our approach blends computer vision and NLP based annotation methods with structured human judgment to assess prompt fidelity, visual artifacts, style and brand alignment, and safety and rights risk. We partner with AI labs, high growth startups, and enterprises to run evaluation across the model lifecycle, from research benchmarking to release gating and production monitoring, at scale.
EVALUATION DIMENSIONS
MULTI-TURN PROMPT AND IMAGE FIDELITY
Evaluation of multi-step prompt–image interactions, including iterative image edits and transformations. Reviewers assess fidelity, intent preservation, and cumulative drift across turns using large, multi-axis rubrics.
AESTHETIC COHERENCE AND
“AI-ARTIFACTS”
Fine-grained assessment of perceptual quality, including subtle indicators of AI-generated content, visual awkwardness, or stylistic inconsistency that emerge only under expert review and extended analysis.
BRAND, STYLE AND DOMAIN
FIDELITY
Custom evaluation rubrics ensure outputs adhere to brand guidelines, visual language systems, and domain-specific expectations.
PROMPT-OUTPUT ALIGNMENT
Reviewers assess whether generated images accurately reflect prompt intent, constraints, and implicit expectations across both language and vision.
VIDEO QUALITY AND TECHNICAL INTEGRITY
Detection of rendering artifacts, anatomical distortions, compositional errors, lighting inconsistencies, and object blending issues.
IP, COPYRIGHT, AND TRADEMARK RISK
ETHICAL, CULTURAL, AND REGULATORY RISK
FACTUAL AND REPRESENTATIONAL ACCURACY

WHY HUMAN-LED PRECISION EVALUATION
Advanced image models tend to fail in nuanced ways. Subtle stylistic drift, near-miss IP violations, implicit bias, and partial prompt misinterpretation often pass automated checks while still creating meaningful risk.
Human evaluation provides the ground-truth signals required to ship image models with confidence, protect brands and users, and generate reliable feedback for model improvement.
WHO WE SUPPORT
iMerit supports both model developers and AI-powered product teams across high-impact domains.
FOUNDATION AND FRONTIER MODEL TEAMS
GENERATIVE AI STARTUPS
E-COMMERCE AND DIGITAL BRANDS
Assess AI-generated product imagery and lifestyle assets before deployment across PDPs, advertising, and marketplaces.
MEDIA GAMES AND ENTERTAINMENT
CREATIVE AND DESIGN PLATFORMS
Maintain consistent visual systems across styles, characters, and content libraries at scale.
CARTOONS & ANIMATION
Validate storyboards and key frames so characters and visual style stay on-model across episodes and panels
HOW IT WORKS

- CUSTOM RUBRIC DESIGN
Brand standards, content policies, and research goals are translated into multi-dimensional evaluation rubrics covering visual, linguistic, ethical, and technical criteria. Our researchers partner with customer researchers to tailor rubrics tailored by domain, language, style, and use case. - EXPERT GUIDED EVALUATION
Generated images flow into iMerit’s multimodal workflows, where trained evaluators apply structured judgments, rankings, and annotations under the guidance of experts from design, VFX, and creative disciplines. - STRUCTURED OUTPUTS AND ANALYTICS
Results are delivered as machine-readable outputs including labels, scores, rankings, and issue tags, alongside dashboards that track trends, volumes, and turnaround times. In complex transformation or image-editing workflows, evaluators may perform detailed side-by-side analysis of source images, prompts, and generated outputs, assessing changes at the level of individual visual elements. - MODEL FEEDBACK AND IMPROVEMENT
Evaluation outputs integrate directly into training, benchmarking, and monitoring pipelines to support RLHF, fine-tuning, and ongoing governance.
EVALUATION AS TRAINING SIGNAL
WITH RLHF & MODEL BENCHMARKING
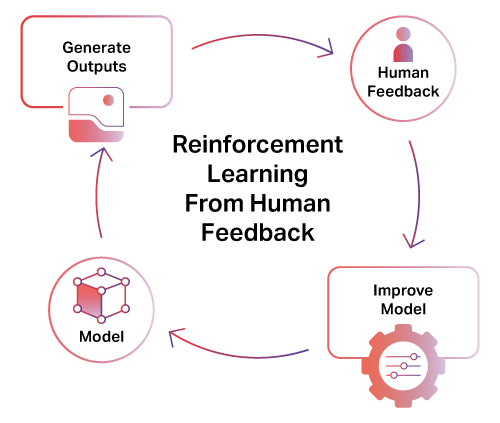
Reinforcement learning from human feedback for image models depends on consistent, context-aware human judgment. iMerit enables large-scale collection of preference data, rankings, and rubric-based scores that reflect real application requirements.
Feedback captures aesthetic preferences, prompt fidelity, ethical boundaries, and domain-specific quality thresholds. This data supports continuous model improvement across research and production environments.
ANGO HUB IMAGE GENERATION EVALUATION TOOL
Ango Hub supports large-scale human-in-the-loop evaluation with configurable workflows and enterprise controls.
- Multimodal annotation and review workflows
- Custom rubric configuration
- APIs and SDKs for integration into existing pipelines
- Secure environments for prompts, source assets, and generated outputs
- Real-time project tracking and QA oversight
The platform is designed to integrate across research, development, and production stages.
WHY CHOOSE iMERIT
iMerit provides high-quality, human-led evaluation that ensures AI-generated images are accurate, brand-safe, and free of errors or bias. Our expert workforce is trained to catch subtle visual issues and compliance risks that automated systems often miss. With scalable teams and proven workflows, iMerit delivers reliable, business-ready image assessments that enhance trust and performance across AI products.

PRECISION EVALUATION DESIGN
Rubrics and workflows are built to reflect specific model behaviors, domains, and risk profiles rather than generic quality checks.
VISUAL AND LANGUAGE EXPERTISE
Evaluation teams are trained and overseen by specialists from design, VFX, and creative fields, bringing deep visual literacy to the process.

GLOBAL SCALE WITH SELECTIVE WORKFLOWS
SECURITY AND OPERATIONAL MATURITY
PROCUREMENT-READY DELIVERY
Frequently Asked Questions
How does iMerit’s image evaluation differ from basic RLHF or QA?
iMerit focuses on rubric-driven evaluation designed for model development and benchmarking, with structured outputs suitable for training, analysis, and governance.
Can you support custom brands, styles, or niche domains?
Yes. Custom rubric design and domain-specific workflows are core to how projects are scoped and delivered.
How do evaluation outputs integrate with model pipelines?
Outputs are delivered in structured, machine-readable formats and integrate via API or SDK into training, benchmarking, and monitoring systems.
Can evaluation scale to very large volumes?
Yes. iMerit specializes in managing large-scale, high-selectivity human workflows for production systems and frontier research programs.
How is quality and consistency maintained?
Expert leads oversee rubric design, evaluator training, calibration, and ongoing quality assurance. Quality Control combines process automation, anomaly detection, and human-led audits.
What is image generation evaluation and why is it important?
Image generation evaluation is the process of reviewing and validating AI-generated images to ensure they are accurate, high quality, brand-safe, and aligned with project goals. It’s essential because AI models can produce subtle errors, bias, or visual inconsistencies that automated tools may miss. Human evaluation helps businesses maintain trust, reduce risk, and improve overall model performance.
What tools can be used for image generation evaluation?
Image generation evaluation typically uses a combination of human review workflows, annotation platforms, and quality-checking tools designed to identify errors, bias, and inconsistencies in AI-generated images. At iMerit, evaluators rely on Ango Hub, an enterprise-grade data annotation and review platform built specifically for high-volume AI assessment. Ango Hub enables teams to label defects, rank model outputs, validate brand alignment, and provide structured feedback that can be fed back into model training. Along with custom taxonomies, workflow automation, and detailed quality controls, iMerit combines advanced tooling with expert human insight to deliver scalable, high-accuracy evaluation for even the most complex image generation pipelines.
READY TO DEPLOY WITH CONFIDENCE?
When image generation is central to your product or platform, evaluation needs to match the sophistication of the model.
Talk to iMerit about precision image evaluation, expert-guided workflows, and multimodal human feedback built for frontier AI systems.