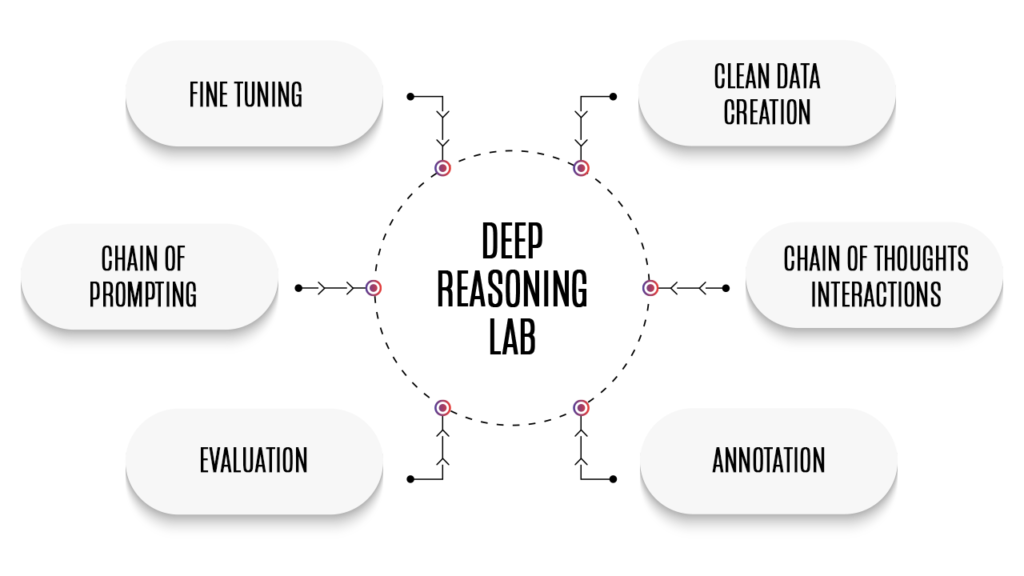
The Chain-of-Thought Framework
Our framework integrates AI reasoning workflows—from data creation and evaluation to model interaction and refinement—into a single, seamless interface. Analysts, experts, and model developers can generate reasoning data, engage with AI models, and assess responses dynamically in one collaborative environment.