Improving Speaker Identification
in Clinical Conversations
This major global software vendor needed help annotating patient and clinician conversations to improve the performance of its digital scribe.
Challenge
During clinical encounters, clinicians take notes to summarize patient interactions that can improve care quality. However, the administrative burden of this critical process causes burnout among clinicians and reduces patient-facing time. To improve care efficacy and efficiency, clinicians employ AI-powered digital scribes to summarize conversations and generate administrative reports.
This major software company needed to improve its model’s ability to establish boundaries between speakers, summarize conversations, and improve clinical data gathering.
As conversations are typically unconstrained, improving the digital scribe’s ability to identify between speakers was an ongoing challenge. Due to the sensitive nature of medical data, this company needed a HIPAA-compliant data annotation provider with natural language processing and medical expertise.
“It’s tough to find medical conversations we can actually use. iMerit proposed a very unique solution to our problem. ”
- Head of AI Solutions
Solution
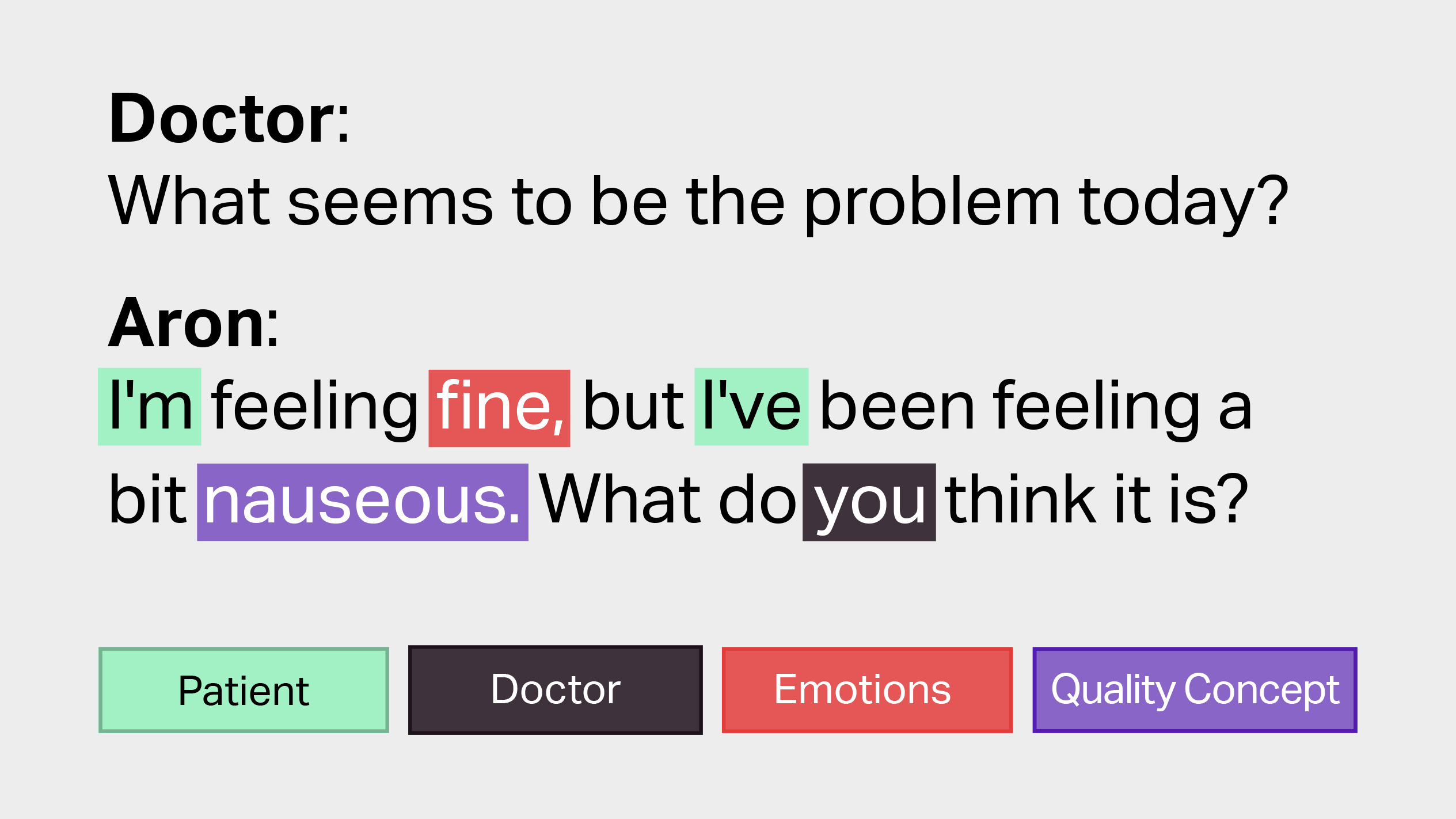
After transcribing 350 conversations, iMerit experts generated large-scale semantic taxonomies using Ango Hub. Parameters were tuned using the Unified Medical Language System, with phrases such as “I am feeling well” resulting in “I” mapped to “patient”, “feeling” mapped to “emotions”, and “fine” mapped to “qualitative concept”, for example.
To ensure HIPAA compliance, iMerit de-identified conversations by removing personally identifiable information. If the removed information was critical to the diagnosis or health record, iMerit’s healthcare experts would generate text that could fit into the rest of the conversation and substitute the removed segments without compromising medical integrity.
To improve boundary identification, iMerit experts suggested annotating conversations around specific topics. For example, if the discussion focused on an allergy, specific question sets were identified across conversations. This topic identification also singled out redundant information, preventing it from entering electronic health records.
After transcribing, de-identifying and annotating these conversations, training datasets were generated to fine-tune the digital scribe.

Result
After implementing the training datasets into the model, quality checks comparing performance before and after fine-tuning indicated a significant +37% improvement to speaker identification, which resulted in a substantial interpretive accuracy metric of 98%.
After training the model, physicians employing the digital scribe technology were able to spend an average of four hours of extra clinic time per week, resulting in more time with patients and improved care. The scribe also structured all conversations into an electronic health record, which physicians could then review and sign off on at the end of their day instead of between patient visits.

Overall, the scribe improved patient-facing exposure for clinicians by 11% after iMerit trained it using the de-identified conversations. Today, iMerit continues to help this company expand their scribe’s horizons against developing diseases and shifting HIPAA guidelines.