In the race to build intelligent systems, the winners won’t just be those with the biggest models, but those with the most aligned ones. Achieving this requires fine-tuning models with human feedback, a process known as Reinforcement Learning from Human Feedback (RLHF). It’s this alignment that transforms raw model outputs into responses that are useful, safe, and trusted.
RLHF helps models learn what users prefer. It improves the quality and relevance of their responses. But as user needs change over time, the data used to train these models can become outdated. This is called data drift. When data drift occurs, the model may no longer behave as expected. Forbes mentions that 85% of AI leaders reported problems caused by data drift in production models.
Let’s go over how data drift impacts RLHF pipelines, but first, let’s understand RLHF. We will also look at how to detect and fix drift while scaling RLHF for large systems.
Understanding RLHF and Its Fine-tuning Context
Reinforcement Learning from Human Feedback (RLHF) is a widely used method for aligning language models with human expectations. It combines supervised fine-tuning, reward model training, and policy optimization techniques like PPO, DPO, or IPO.
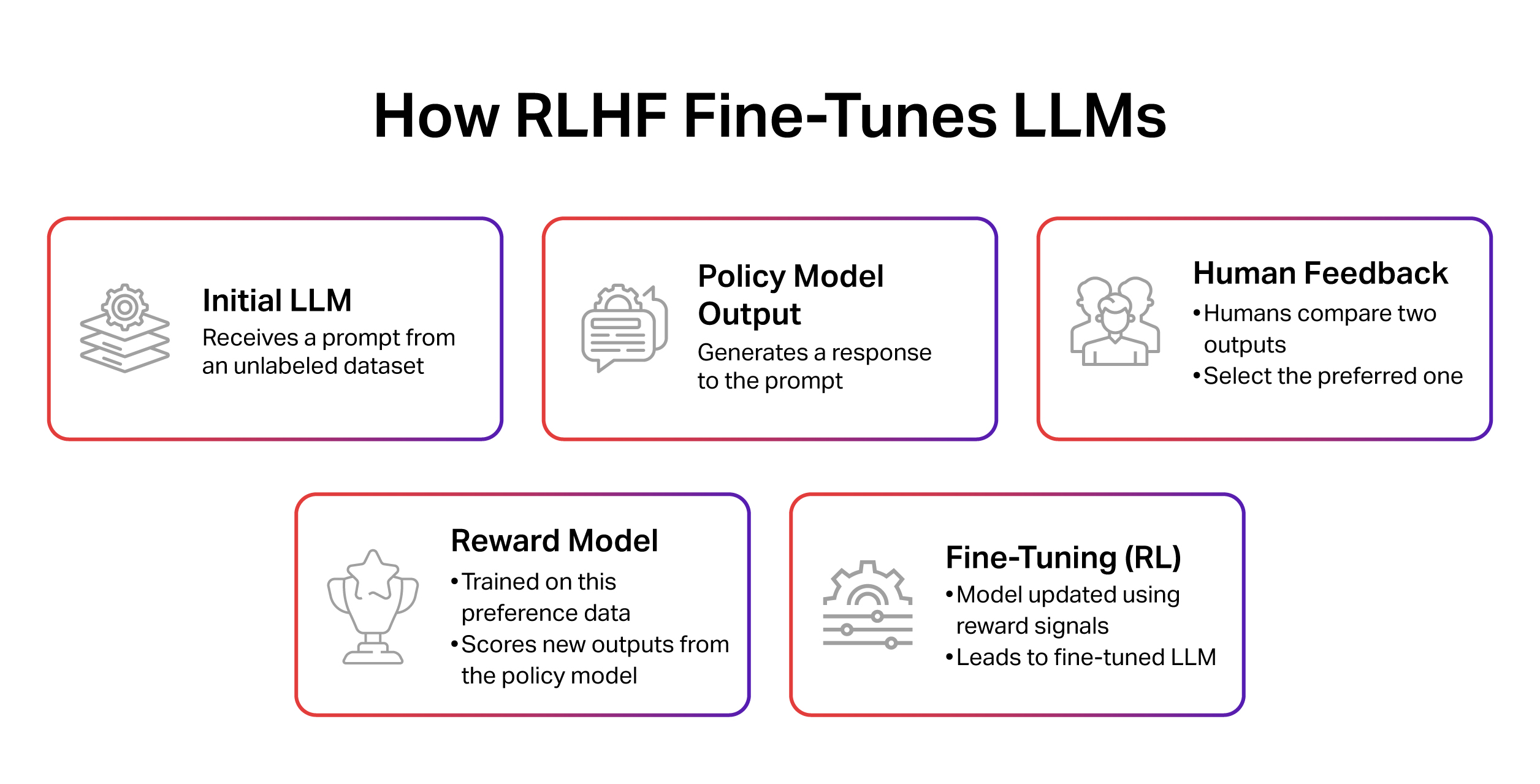
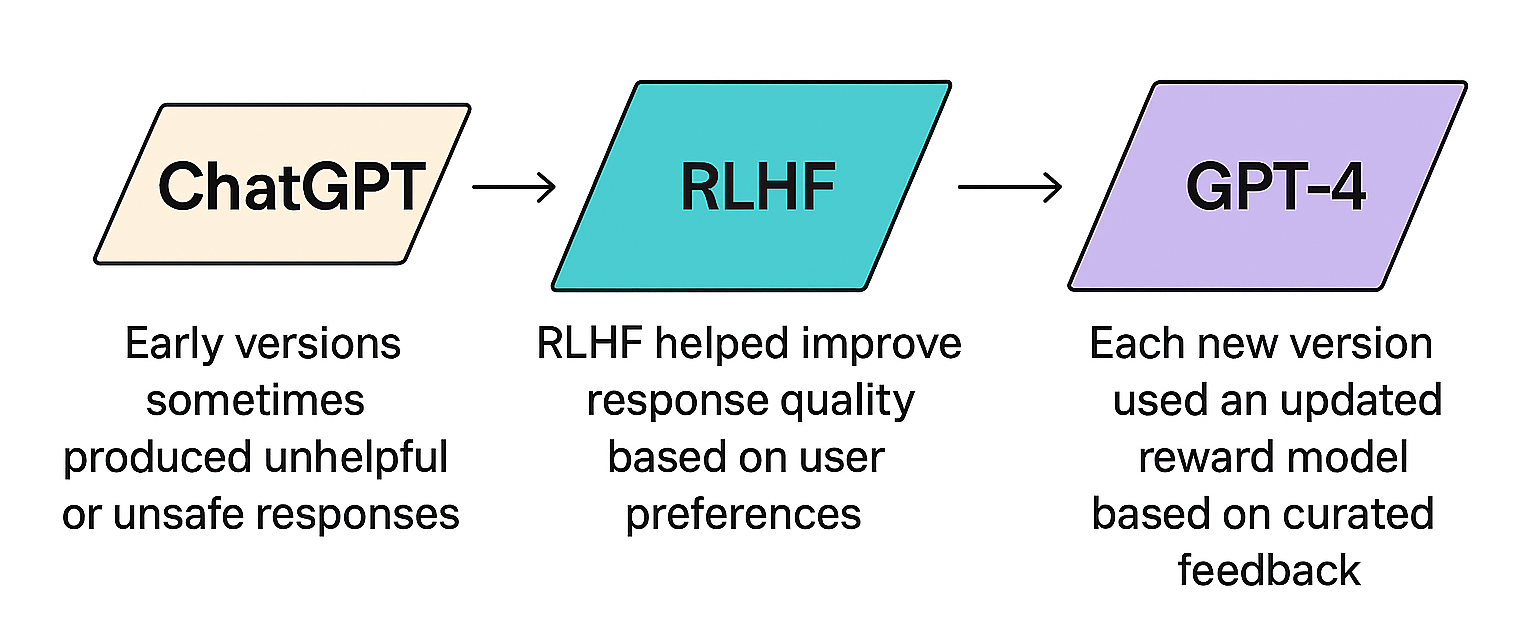
The real value of RLHF lies in the impact. It helps reduce bias, improves instruction following, and makes model outputs more useful in complex or subjective scenarios. For example, early versions of OpenAI’s ChatGPT sometimes produced responses that were unhelpful or unsafe. RLHF helped improve the quality of those responses by learning from user preferences. Each new version, including the shift from GPT-3.5 to GPT-4, used updated reward models based on carefully curated feedback to better align outputs with human expectations.
Challenges in Scaling RLHF
As large language models grow, scaling RLHF becomes more and more challenging. Here are some key challenges:
- Training large models and reward systems takes powerful hardware. The RL step, in particular, consumes considerable time and energy.
- RLHF needs many high-quality human-labeled examples. This makes scaling the feedback process without compromising quality a complex issue.
- Fine-tuning with reinforcement learning can sometimes lead to unexpected behaviors or reduce the model’s reliability. It might forget previously learned skills, which can undermine its performance in real-world scenarios.
However, one of the biggest ongoing challenges is data drift, which we will explore in the sections below.
The Problem of Data Drift in LLM Fine-tuning
Data drift refers to a change in the distribution of data over time, creating a mismatch between the data a machine learning model was trained on and the data it encounters in real-world use. This can include changes in the type of questions users ask, the way people write prompts, or how they judge good responses.
When this shift occurs, the model may give less accurate or less helpful answers because it is no longer learning from data that reflects current user needs. In RLHF pipelines, this can lead to poor alignment, unstable training, and more work for human reviewers.
There are different types of data drift:
- Covariate Shift: In this type of drift, the prompts given to the model change. Users start asking about new domains, trends, or using a different language than what the model was trained on.
- Concept Drift: The definition of a “good” response changes. What users once considered helpful may now feel outdated, verbose, or insensitive.
- Label Drift: Human annotation behavior evolves. Annotators may start judging similar outputs differently due to new guidelines or norms.
Manifestations of Data Drift in RLHF Pipelines
Data drift can show up in several ways within RLHF systems. Here is how it happens:
Prompt Distribution
The types of questions or “prompts” users give to the LLM can change.
For example, A model is fine-tuned on general knowledge questions. Later, the users start giving prompts about Web3 smart contracts or AI-generated content policies. The model has not been trained to handle them accurately. As a result, the prompts seen in production may no longer match the distribution the model or reward system was trained on.
In the LLM’s Output Distribution
As large language models are fine-tuned, they begin to produce more complex and creative responses. While this is usually a good thing, it can cause a gap between the newer outputs and the Reward Model’s original training data. Since the Reward Model was trained on simpler responses, it may have trouble evaluating the new ones accurately, leading to inconsistencies in scoring.
Reward Model’s Training Data
The Reward Model learns how to evaluate new responses based on past human feedback and previous LLM outputs. However, as the LLM evolves, the training data for the Reward Model may no longer match the model’s current behavior. This creates outdated feedback loops, where the Reward Model gives inaccurate evaluations because it hasn’t been updated to reflect the model’s latest changes or improvements.
Human Preferences Themselves
Human preferences themselves can shift over time. What users consider a “good” response might change as cultural, technological, or personal factors evolve. As a result, the feedback collected in earlier stages of model training may no longer accurately reflect current expectations or preferences.
If the system does not account for these shifts in user expectations, the feedback used for fine-tuning the model becomes less relevant.
Consequences of Data Drift
When data drift occurs, several problems can arise:
- Reward Model Accuracy Drops: The Reward Model becomes less accurate. It struggles to give correct scores to the LLM’s new outputs.
- LLM Performance Worsens: As drift increases, the LLM can start producing answers that are off-topic, outdated, or even unsafe. For example, an LLM trained to assist with general coding questions may give outdated advice when users start asking about new frameworks like Bun or Astro. It’s because the reward model has not seen or learned to value those newer topics.
- Training Becomes Unstable: PPO and other RL algorithms rely on stable reward signals. When those signals become noisy or misleading, the training process becomes unstable. The model may start to overfit, collapse into repetitive patterns, or stop improving altogether.
- More Human Work: When data drift occurs, companies will need more human annotators to fix the problem. This adds to the cost and effort. They may even have to retrain reward models from scratch, just to catch up.
Strategies for Overcoming Data Drift
Data drift poses a major challenge for LLMs, but there are effective strategies to handle it. The goal is to keep LLMs functioning optimally as the data they encounter evolves. To achieve this, we need to detect drift early, collect relevant new data, update our models, and establish adaptive systems that can handle these shifts. Here are a few effective strategies for overcoming data drift:
Drift Detection Techniques
To track data drift, it is important to note how both inputs (prompts) and outputs change over time. Here are some key ways to detect drift in RLHF pipelines:
- Monitoring Output Distributions: As the LLM evolves, its outputs may shift in tone or structure. Some of these changes are good, but others may signal drift. To track this:
- Teams use statistical tools like JS divergence or Wasserstein distance. These compare current outputs to earlier ones by analyzing their sentence embeddings. If the difference grows too large, it may mean the model is drifting from expected behavior.
- Another useful signal is the reward model RM score distributions. If the RM starts scoring outputs very differently from before, that is a sign that the model’s behavior has changed beyond what the RM was trained to judge.
- Perplexity can also help. If the model’s perplexity on new prompts keeps rising, it might be struggling to understand the current user language.
- Tracking Prompt Evolution: Prompt drift happens when users start asking about new topics or using different language patterns. To spot this, use LDA or K-means on prompt embeddings to detect emerging themes. If many prompts fall into new clusters, it may be time to update the training data or reward model. When Anthropic launched Claude, prompts shifted toward longer, context-heavy tasks like policy writing and therapy advice. Tracking this helped them focus on new data collection.
- Human Feedback Loop Analysis: Monitor annotator agreement rates. A drop in agreement may mean the model’s outputs are harder to judge or less aligned. Changes in labeling patterns often indicate concept drift in human values or expectations. Also, watch for preference flips, where labelers now prefer completions they used to reject.
| Method | Metric/Tool | Best For |
|---|---|---|
| Statistical Distance Metrics | JS Divergence, KL Divergence | Output distribution shifts |
| Embedding Similarity Analysis | Cosine/Wasserstein distance | Semantic-level drift detection |
| Prompt Evolution Analysis | Cluster analysis, topic modeling | Tracking input changes over time |
| Feedback Consistency Monitoring | Annotator agreement %, RM confidence | Validating preference data consistency |
Adaptive Data Collection and Curation
Once drift is identified, it’s important to collect the right data to correct it.
- Active Learning for the Reward Model: The system should focus on labeling examples where it is most unsure. This helps improve learning where it matters most.
- Curriculum Learning for Prompts: Introduce new or harder prompts slowly to help the model adapt without confusion. This gives it time to learn more complex patterns.
- Data Versioning and Governance: Keeping track of what data was used and when helps with audits, debugging, and improving trust in the system.
Model Adaptation and Retraining Strategies
After collecting new data, we update our LLM.
- Continuous or Online Learning: This involves updating the model step by step with new data. However, care must be taken to avoid “catastrophic forgetting,” where the model loses old knowledge. Human-in-the-loop validation is key. iMerit Scholars, domain experts with metacognitive training, provide feedback to prevent catastrophic forgetting and maintain alignment during retraining.
- Scheduled Retraining: This includes retraining the model at regular intervals or when drift is detected. It’s more controlled but takes more time and resources.
- Ensemble Methods for Reward Models: Using multiple reward models trained on different data helps reduce the risk of overfitting and increases robustness.
- **Robust Reinforcement Learning Algorithms**: Some reinforcement learning methods are less sensitive to noise or drift. These methods help maintain stability in the model even when the reward signal changes slightly.
Architectural Considerations for Scalability
To manage RLHF at scale, you need the right systems and tools in place. A strong setup helps you handle data drift and model updates more easily.
- Modular Pipeline Design: Break the system into separate parts. These include Supervised Fine-Tuning SFT, Reward Model RM, and Reinforcement Learning RL. Each part should be able to update without affecting the others. This makes it easier to fix problems, test improvements, or retrain one component without starting from scratch.
- Automated Data Pipelines: Use automated tools like iMerit’s Ango Hub to collect, clean, label, and manage data. This reduces manual work and lowers the risk of errors. It also helps keep up with fast-changing prompts and user needs.
- Distributed Training Frameworks: Large models and datasets require training across many GPUs or machines. Use frameworks like FSDP or DeepSpeed to split the work and make training faster and more efficient. This helps scale RLHF to support larger models and more frequent updates. For example, Google’s Gemini team uses a distributed infrastructure across TPU pods to train and fine-tune models with massive preference datasets, enabling fast iteration at scale.
- Infrastructure for A/B Testing and Rollbacks: Before fully launching a new model or reward function, test it with a small group of users. Compare it against the current version to measure improvement or detect issues. Keep older versions ready so you can roll back quickly if something goes wrong.
Scaling RLHF: Infrastructure and Data Strategies
Scaling RLHF demands systems that can handle large volumes of data and feedback, without slowing down model development. This involves smart infrastructure choices and efficient ways to collect and process training data.
Distributed Data Collection Systems
When you’re gathering feedback from millions of users, relying on a single source isn’t enough. That’s where distributed data collection systems come in. These systems enable data collection from diverse regions, user groups, or devices, ensuring efficient gathering of:
- User Interactions: What questions are people asking? How are they interacting with the LLM?
- Model Responses: What answers is the LLM giving?
- Human Preferences: Which answers do people like best?
These systems spread the work across many computers and teams to help collect large amounts of data efficiently.
Role of Feedback Tools
Collecting high-quality human feedback is a key part of RLHF pipelines. To do this at scale, teams use dedicated tools that allow annotators to score, rank, or comment on model outputs. Open-ended annotation interfaces capture both the rating and the reasoning behind it.
Active learning systems can be built into these tools to help prioritize which samples are most important to label. iMerit offers trained annotators and custom feedback workflows that support RLHF pipelines.
Our human-in-the-loop services can deliver structured and open-ended feedback at scale to help model developers improve quality, reduce bias, and maintain alignment as their models evolve.
Using Synthetic Feedback
To expedite the scaling process, teams often incorporate synthetic data. This refers to the responses generated by earlier models to simulate real human feedback. Doing so can be useful when human feedback is scarce. However, caution must be exercised when using synthetic feedback to ensure that errors from the previous models do not propagate into new ones.
Practical Considerations and Best Practices
Making RLHF pipelines work well in the real world involves more than just technical solutions. It also requires smart planning and best practices.
- Human-in-the-Loop Optimization: Human experts play a central role in the RLHF process. They provide the invaluable feedback that guides the LLM and helps it align with human preferences. Their input is key for allowing the model to understand and replicate complex human values and behaviors.
- Cost-Benefit Analysis of Retraining: Updating and retraining LLMs and Reward Models takes time and money. It uses a lot of computing power and human effort for data annotation. It is important to weigh these costs against the benefits. Sometimes, a small amount of drift might not need a full retraining. However, a substantial drift might require a major update to keep the LLM useful.
- Tooling and Infrastructure: Specialized platforms make it easier to manage feedback and training data. For example, iMerit’s Ango Hub can help to organize human reviews, track quality, and manage annotation tasks at scale. These tools enable faster iterations and improved model performance. This helps support continuous improvements in RLHF pipelines.
- Measuring Success: Clear metrics are needed to track progress. These may include alignment scores, model consistency, or how often humans agree with the model’s outputs. You can also use standard metrics like precision, recall, F1 score, and Mean Reciprocal Rank (MRR) to measure how well the model selects preferred responses. Strong metrics help spot problems early and guide improvements.
- Ethical Considerations: Data drift can sometimes lead to bias or unfair results. It’s important to keep an eye on these issues during the training and feedback process. Human reviewers are key to spotting any risky outputs. They help ensure the model stays safe, fair, and aligned with ethical standards by flagging potential problems before they get too far.
Conclusion
Scaling RLHF is not easy, but it is important. As large language models become part of more tools and services, we must keep them aligned with human needs.
Here are the key takeaways:
- RLHF helps align large language models with human preferences.
- Data drift affects input prompts, model outputs, and human feedback.
- Early detection and smart updates help keep models aligned.
- Human experts play a key role in reviewing and guiding model learning.
- The right tools, like iMerit’s Ango Hub, support scale and quality.
For example, iMerit helped a leading technology company improve model alignment using RLHF. Their expert annotators ranked LLM responses to fine-tune the reward model. The result was more accurate and human-like outputs at scale. Read the case study here.
Connect with iMerit to explore customized RLHF & drift monitoring solutions.