Large Language Models (LLMs) have become central to Artificial Intelligence (AI) advancements in various applications, such as chatbots and healthcare diagnostics. Modern AI developers often rely on automated metrics, such as accuracy, BLEU, and perplexity, that provide quick insights into how a language model responds to human prompts.
However, many automated metrics often miss the deeper qualities that determine if the output of an AI model is truly valuable, i.e., its helpfulness, truthfulness, and safety in real-world settings.

To address this issue, benchmarks, also known as standardized tests, are now used to track LLM progress and ensure that their outputs align with human values. However, a key limitation of most standardized benchmarks is their reliance on automated metrics, which often overlook subtle nuances, creativity, contextual understanding, and ethical considerations.
As LLMs scale and become increasingly crucial for decision-making in complex and high-stakes domains, such as healthcare, finance, and law, more comprehensive AI evaluation methods are essential. For instance, in healthcare, accurate medical text understanding can impact patient safety, making large-scale human judgment a key part of the assessment process. Therefore, by adding large-scale human judgment to LLM assessment, we can get more reliable, nuanced, and human-aligned measures of AI capabilities.
To bridge this gap, we will explain why automated metrics alone are insufficient. We will also explore how expert human evaluation, combined with automation, is now redefining AI model testing for next-generation LLM benchmarks.
The Role of Human Judgment in LLM Evaluation
Human evaluators are considered the gold standard for assessing LLM outputs. Unlike automated algorithms, humans can detect subtle shortcomings such as tone mismatches, false claims, irrelevance, factual inaccuracy, inappropriate language, and misalignment with instructions..
As these qualities directly impact user trust and safety, human evaluation becomes necessary. Such evaluation can include rating the helpfulness and clarity of a response, checking if it fits the context, and spotting any potential biases.
However, human evaluation also faces several challenges. Individual reviewers often disagree because open-ended language tasks are subjective, e.g., one annotator might find a response friendly, while another sees it as too cryptic. Due to the subjectivity, personal and cultural biases of the annotators, it can influence judgments, and the slow, expensive hiring and training process makes manually evaluating millions of outputs an unscalable solution.
To address these challenges, teams use strategies to improve reliability; for instance, they assign multi-rater systems where several evaluators review the same content and apply consensus scoring to reduce variability. Moreover, they develop detailed guidelines and rubrics so annotators rate things consistently.
One example comes from medical annotation teams by iMerit. These experts use established guidelines and real-time quality checks to annotate electronic health records, significantly improving the consistency and accuracy of medical AI evaluation.
To scale this approach, structured crowdsourcing can be used, but with rigorous quality checks. This includes methods like trial questions and expert oversight to filter out noisy labels. Ultimately, while human judges offer deeper insight, the process has to be carefully structured to ensure reliability and fairness.
Tasks Involved in Human Evaluation
There are some key checks that human reviewers need to perform to measure how well the output of the model meets standards, such as:
- Helpfulness: Assess whether the answer of the model is genuinely useful to the user’s question or task.
- Factual Correctness: Check if the information provided by the model is accurate and truthful.
- Contextual Relevance: Verify the response is appropriate and fits the context in which the question was asked.
- Adherence to Task Goals: Ensure the answer satisfies all parts of the prompt or task, sticking to instructions.
- Bias Detection: Identify any signs of bias or unfair assumptions in the output.
- Inter-Rater Consistency: Regularly compare scores from different reviewers to ensure reliable and fair benchmarking.
Understanding Traditional LLM Benchmarks and Their Challenges
Traditional LLM benchmarks typically rely on objective but narrow automated metrics and fixed test sets. Common examples include:
- Multiple-choice question sets for measuring simple accuracy on simple tasks.
- BLEU or ROUGE scores for evaluating translation or summarization by comparing to reference texts.
- Perplexity is used to measure how well a model predicts the next text token in a language modeling task.
While these benchmarks are inexpensive and easy to reproduce, they face significant limitations, such as:
- Data Contamination: Models trained on vast datasets can “memorize” benchmark content, artificially inflating scores and masking real weaknesses, instead of reasoning or understanding.
- Ecological Invalidity: Many benchmarks fail to replicate real-world complexity, such as ambiguous language, noisy data, or multimodal inputs involving images and speech.
- Limited Scope: These traditional metrics struggle to capture creativity, multi-step reasoning, coherence, or ethical alignment.
- Narrow Focus: Most benchmarks primarily test text-based tasks. However, human judgment evaluation methods are now being extended to multimodal models that can handle texts, images, audio understanding, and even code generation, making robust evaluation practices even more essential.
- Overfitting to Metrics: Overfitting to specific scores can lead to brittle models that “game” the tests rather than genuinely improve.
Over-reliance on these narrow measures can lead to misleading LLM assessment, giving teams a false sense of model improvement where none truly exists. To widen evaluation coverage, the AI research community now uses broader benchmarks such as Holistic Evaluation of Language Models (HELM), covering multiple axes like ethics, robustness, and reasoning, and Beyond the Imitation Game (BIG-bench), a large task suite probing diverse model capabilities.
Traditional benchmarks are useful; however, they rely heavily on human judgment for subtle, subjective, complex reasoning and ethical aspects. To fully evaluate LLMs, especially multimodal ones, we need human-aligned assessment alongside automated metrics.
Integrating Human Judgment at Scale into LLM Benchmarks
Scaling human judgment for LLM assessment is complex and resource-intensive. The industry and research teams have developed hybrid frameworks using selective automation, prioritization, and targeted human annotation to optimize both cost and AI evaluation. For instance, iMerit’s use of active learning with medical experts for LLM validation improves both efficiency and reliability.
A practical hybrid workflow often includes:
Automated Pre-Screening (Triage)
Run quick, automated checks to filter out clearly good or clearly bad responses. For example, you might test for errors, such as whether the code compiles, use standard metrics, or have another LLM act as an automatic reviewer (i.e., LLM-as-judge). This way, you can easily eliminate obvious successes and failures, and focus human review on the complex cases that need attention.
Active Sample Selection
Next, use active learning to pick the most informative examples for human review. For instance, in a summarization task, a model’s output might score high on ROUGE (matching many words from the reference) but still miss the main meaning, resulting in a low BLEU score. Such conflicting scores signal that human review is needed to judge the true quality of the summary.
Expert Human Annotation
Domain experts or trained annotators, such as iMerit scholars, then review the selected samples in depth. They follow detailed, structured guidelines to rate each response on multiple dimensions that measure helpfulness, factuality, and safety. Workflows may involve multiple rounds: if the initial annotators disagree, a senior expert reviews the case (adjudication). The granular scoring rubrics (e.g., 1-5 scales with examples for “correct”, “helpfulness”, “risk”) reduce subjectivity.
Multi-Phase Quality Assurance
Finally, teams use multi-phase quality assurance. This includes consensus logic (e.g., average or majority vote if 3-5 annotators rated the item), calibration rounds (where annotators discuss disagreements to fine-tune the rubric), and analytic monitoring of inter-rater reliability.
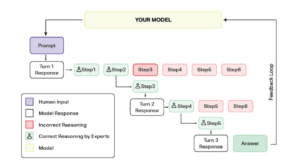
The above hybrid pipeline keeps costs down while preserving human nuance where it matters most. Further, a platform like iMerit’s Ango Hub can help streamline such workflows. It combines automation and human-in-the-loop processes so that scripts or simpler reviews can handle routine checks or model predictions. Also, healthcare professionals can use the active learning feature by iMerit, combined with expert medical annotators, to evaluate healthcare LLMs, improving the accuracy and trustworthiness of clinical AI models.
Beyond human labels, recent benchmark initiatives also make it easier to scale and standardize hybrid evaluation. For instance, Judge-Bench and GRE-bench provide large, publicly available datasets and scoring systems that allow both humans and LLMs to be evaluated side by side.
This promotes consistency and transparency, and enables larger-scale comparison by the broader community. Additionally, benchmarks like HELM and BIG-bench include instructions for scalable human reviews, further supporting reliable multi-annotator workflows.
Challenges and Ethical Considerations
While the earlier sections discussed challenges in implementing human evaluation workflows, human-integrated benchmarking at scale introduces some additional systematic and ethical challenges that organizations must address. These broader challenges affect not just the evaluation process itself, but the entire AI development lifecycle and regulatory compliance. Some of them are:
- Data Contamination: Sometimes, benchmark test data leaks into the model training sets, leading to unrealistically high performance and masking weaknesses, even with human involvement. However, new benchmarks reduce this risk by constantly updating test data that human reviewers can check, like recent peer reviews or real-world user queries. They can also flag suspicious outputs, making it harder for such leaks to go unnoticed.
- Robustness to Real-World Use: Human evaluations are often conducted on clean, curated data, but the models in a production environment lack tests for diverse, noisy, or domain-specific conditions, limiting generalizability. Incorporating real-world conditions, such as noisy or adversarial inputs, is vital for generalizable evaluation.
- Scalability of Human Evaluation: Human labeling is resource-intensive and delays rapid model iteration cycles. However, investing in thorough human review mitigates risks of deploying unsafe or inaccurate models that could cause misinformation, regulatory penalties, or reputational harm. iMerit’s hybrid annotation platforms aim to balance this cost-risk trade-off by combining automation with expert human insight.
- Human Bias and Consistency: Humans introduce subjectivity and cultural bias. To combat this, best practices include using diverse, well-balanced teams of annotators, clear guidelines, blind-review procedures, and frequent consistency checks.
- Ethical Risks and Compliance Challenges: Ensuring fairness, transparency, and inclusivity in evaluation is a challenge, particularly in preventing models from reflecting harmful stereotypes or biases. Meeting requirements from regulatory bodies, such as the European Union’s Artificial Intelligence (EU AI) Act and the National Institute of Standards and Technology’s AI Risk Management Framework (NIST AI RMF), also means every evaluation must be well-documented, reproducible, and fit for real-world audits.
Modern benchmarking must meet both technical and societal standards. Evaluations need to guard against biases, ensure inclusivity, and provide evidence that models are safe.
Future Innovations in Human-Integrated LLM Benchmarks
AI evaluation research continues advancing toward deeper human-alignment and regulatory compliance, focusing on three core areas:
- Humanlikeness Evaluation: New benchmarks, such as the Human Likeness Benchmark (HLB), test how closely LLM outputs match human writing and reasoning styles across psycholinguistic experiments. This encourages more natural and trustworthy AI communication.
- Programmatic Task Benchmarks: These benchmarks organize different kinds of human feedback, like preferences, corrections, and explanations, and use them to automatically evaluate AI models. They help automate complex tasks such as code generation, summarizing text, and reasoning, while still relying on human adjudication to ensure correctness, reasoning, and ethical considerations.
- Human-AI Collaborative Benchmark Refinement: Humans use LLM-generated candidate judgments to iteratively refine evaluation criteria, creating adaptive benchmarks that evolve and improve over time. These hybrid methods produce faster, richer benchmarks and allow human judgment to scale while keeping a human in the loop for final decisions.
New AI regulatory standards, e.g., the EU AI Act and like NIST AI RMF for high-risk AI systems, require transparent benchmarks, thorough documentation, oversight by human reviewers, and clear processes for managing fairness and risks. This shift positions benchmarking as a strategic element in trustworthy AI development.
Conclusion
Reliable LLM assessment today demands a balance of automated metrics and scalable human judgment. Automated scoring provides scale and reproducibility, whereas human evaluators contribute nuance, ethical oversight, and domain expertise. A blended approach, such as the hybrid evaluation pipelines used by iMerit, supports deeper oversight and better results in AI model testing.
Key Takeaways
- Automation alone misses critical errors; human judgment improves evaluation accuracy.
- Hybrid workflows enhance cost-efficiency without compromising depth.
- Expert annotation services are essential for credible AI safety benchmarks.
For high-stakes deployments like LLMs used in healthcare or finance, investing in structured human evaluation is not optional. The industry must invest in scalable inter-rater consistency practices and modern platforms to build reliable benchmarks and trustworthy AI.
Partner with iMerit to access expert human evaluation solutions that elevate your LLM benchmarking framework and build trustworthy AI systems.