
Machine learning systems live in a changing environment. An ML system trained up and ready to go may give great results when initially deployed, but its performance can degrade over time due to drift. According to the 2021 IBM Global AI Adoption Index, 62% of businesses surveyed cited ‘Unexpected performance variations or model drift’ as the biggest AI model performance and management issue businesses are dealing with. Managing drift successfully depends on maintaining access to high-quality, precisely annotated training data that adapts as operational environments evolve.
The Impact of Drift on Machine Learning Performance
Drift refers to degradation in an ML system’s performance due to changes in its operational environment. An ML system’s architecture and training data embody assumptions about its environment, and when these assumptions no longer reflect reality, the ML system no longer meets its objectives.
There are two types of drift as it relates to the basic components of an ML system: concept drift and data drift. Using these categories helps us clarify the range of drift mitigation strategies.
While the existence of drift and its impact are universally acknowledged, the terminology used to discuss it is not standardized. What we refer to as data drift is sometimes called covariate shift, and data drift is sometimes referred to as feature drift.
The discussion of drift is further complicated because even though a variety of types can be identified and named, in practice, these types overlap and exist in combination. For example, model drift and model decay are often used to describe drift that can be either concept drift or data drift or both.
To dig deeper, let’s first look at the basic components of an ML system and how they can be affected by drift.
Figure 1 below depicts an ML system in terms of three components:
- Feature extraction, which transforms aspects of the operational environment into representative numerical data, serves as the independent variables for input to a machine learning model. Feature extraction can produce datasets such as arrays of pixels, audio waveform samples, or coded text embeddings that represent data streams that are the model input
- Model encoding, which maps patterns in the numerical input data to target variables and relevant numerical output data. This is the core of the ML system. It consists of a basic ML architecture, typically a deep learning network such as a convolutional neural network or a transformer; hyperparameters, specifying details of the layers and units in the basic architecture; and parameters, optimized through training, typically using a backpropagation with an optimization algorithm such as ADAM
- Output decoding, which converts the ML model’s numerical output data to a form useful to the consumer of the ML system’s output, be it a person or another machine process.
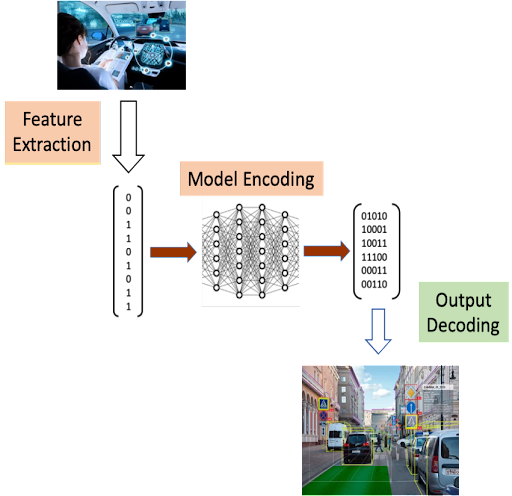
Figure 1. Basic components of an ML System
In the example depicted in Figure 1, at the top we have the ‘real world’ of the operational environment, a vehicle navigating in traffic. Various sensors and their associated processors perform feature extraction by converting the scene and situation into quantities for input to the ML model.
The ML model has been optimized through training to map its inputs to relevant outputs, which is the essence of model encoding. In this example, the ML model’s output is a set of numbers representing a list of identified objects and the coordinates of their bounding boxes. Output encoding converts this set of numbers to an image showing the identified objects and their bounding boxes.
Drift is the result of unanticipated changes in the operational environment that impact the first two ML system components, feature extraction and model encoding. (The third component, output decoding, is not directly affected by drift since it is fixed by the data scientist or ML system designer. However, the designer may elect to change model encoding in response to drift, for example to provide additional detail in the ML system’s output so downstream processing can better respond to drift.)
When a formerly well-performing ML system starts to give bad results, drift is the likely culprit. Something has changed from the baseline represented by its initial training and testing that prevents the ML system from producing accurate, useful outputs in response to the situations it encounters in its operational environment.
Types of Drift: Data Drift vs. Concept Drift
We now look at two types of drift: concept drift, which impacts both feature extraction and model encoding, and data drift (sometimes referred to as covariate shift), which primarily affects feature extraction.
Concept Drift
Developing an ML system requires a comprehensive understanding of the operational environment. We need to know what quantities, objects, entities, and actions will be encountered, which ones are important, and how their characteristics need to be mapped to the ML system output.
ML system developers use their understanding of the operational environment to identify inputs, design models, acquire training data, and perform testing to ensure the ML system makes accurate decisions based on its inputs.
This is depicted below in a simple use case we will use as an example, a machine learning system that is used to assess tolls on a bridge; pedestrians pay $.50, and cars pay $1.00.
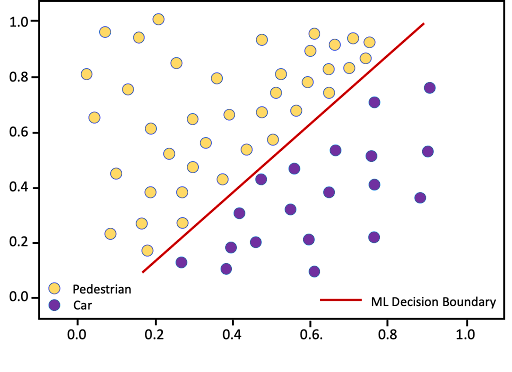
Figure 2. ML model accurately distinguishing pedestrians and cars based on two features
The diagram above depicts data points from two features that have been extracted from the operational environment. Along the vertical axis is a measurement inversely proportional to object size (brightness of video frames, which is smaller with the occlusion of large objects). The horizontal axis represents a metric proportional to object velocity, derived from a radar device. The ML model has been trained to implement a linear decision boundary, allowing it to accurately differentiate pedestrians from cars. The system provides its assessment to a toll collecting machine that automatically displays the correct toll amount, collects the toll, and opens a toll gate to provide access to the bridge.
During the first months of operation, this ML system performed very well; tolls were accurately assessed, and the Department of Transportation (DOT) received very few complaints of mistaken toll assessments. However, after the first of the year, complaints to the DOT began increasing. A significant number of people were claiming they were being overcharged.
The transportation department called in the ML system developers to investigate. The developers knew their system used a thoroughly trained model that reflected a large historical data set with a wide variety of pedestrians and cars. They were puzzled by the sudden decrease in model accuracy.
What they discovered was that the town had begun allowing people on bicycles to use the bridge. The bicyclers were to be charged the pedestrian toll. When they looked at recent records of feature measurements and compared them to recorded video, they discovered a pattern like this:
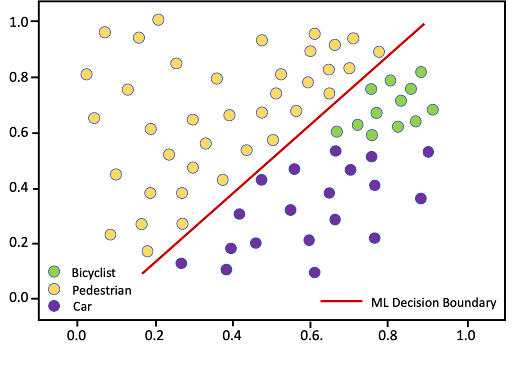
Figure 3. ML model leads to wrong toll for bicyclists
It was clear that based on size and velocity, some bicyclists were being mistaken for cars and assessed the higher toll. The change in bridge policy to allow bicyclists and consider them ‘pedestrians’ for the purpose of toll collection was a fundamental change in the ML system’s operational environment.
A change this fundamental is an example of concept drift. The operational environment has changed so much that the sensed features and ML model no longer allow accurate decisions to be made.
Fixing concept drift can require finding new features, changing the ML model, or both. For the toll system, the developers found that it was possible to retain the same two features and use a non-linear ML model that implemented a more complex, nonlinear decision boundary, as shown below.
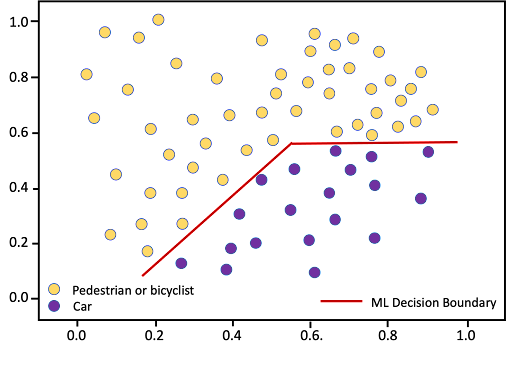
Figure 4. Nonlinear decision boundary to correct for concept drift
(Alternatively, the ML system developers might have used different or additional features that would have allowed continued use of a linear ML model.)
In summary, concept drift involves a change in the operational environment that is significant enough to require a change in the design of the ML system. The ML system ‘concept’, represented by features and the machine learning model, is no longer valid.
Data Drift
In some cases, drift is due to changes in the operational environment less radical than those behind concept drift. Typically, this results in data changes that impact the feature extraction component shown in Figure 1 above, changing the statistical properties of the inputs to the ML model. Examples of changes that can affect feature extraction include measurement instrument recalibration, changes in lighting, degrading data quality, or language trends that shift meanings important to sentiment analysis.
This type of drift does not represent a fundamental change in the ML system’s operational environment. In the real world, entities and actions may have retained their distinguishing characteristics and relationships. However, the probability distribution of the inputs to the ML model, the feature distributions, has shifted. This is called data drift.
For the toll system example, we might imagine an upgrade to the sensors creating inputs to the ML model – a camera with a new focal length and a newly calibrated radar speed sensor. After the new sensors were installed and new data collected, the feature space patterns looked like this:
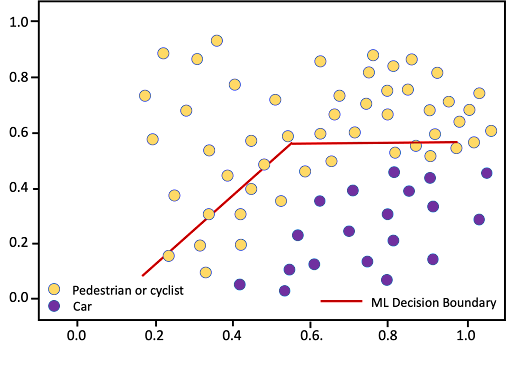
Figure 5. Data drift due to new sensors
In this case, the performance of the ML system could be corrected by model training with data from the new sensors, which shifted the decision boundary to be consistent with the new sensors, as shown in Figure 6 below.

Figure 6. Data drift corrected through retraining
To summarize, data drift is a change that mostly affects feature extraction, and it can generally be addressed by retraining.
Detecting and Monitoring Model Drift
Most operational ML systems operate in an environment that is complex enough that drift is to be expected. It is therefore important to be looking for drift and determining when action needs to be taken to correct its effects.
Here we divide the approaches to detecting drift into two categories:
Output Validation: detecting drift by monitoring the accuracy of the ML system’s output
System Monitoring: detecting likely drift by analyzing intermediate quantities produced during ML system operation.
If we can determine through output validation that an ML system’s output is becoming inaccurate, it’s a sure sign that drift is taking place. Although in many situations this is the best indicator of drift that we can get, we may be finding out about drift only after business operations have been negatively affected. In the toll system example above, it took customers complaining to alert developers to drift.
In some cases, system monitoring can give us earlier indications of drift. System monitoring can also give us information that helps differentiate between data drift and concept drift, and it can help automate the forecasting of drift.
Output Validation Techniques
Output validation detects drift by making a ‘sanity check’ on an ML system’s output. Here we describe how this can be done at three levels in an ML system’s operational context.
At the highest level, drift can be detected by monitoring downstream effects on business processes. For example, if an ML system drives a customer service chatbot, customer satisfaction metrics such as surveys, complaints, and repeat sales can identify potential problems with the ML system.
Detecting drift though its ultimate effect on business is a blunt instrument. We may not notice drift until there are serious consequences. Also, it may be difficult to sort out the effects of ML system performance from other business factors. And one might argue that monitoring business metrics is routine and not really focused on ML system drift.
However, the key here is to acknowledge, identify, and track the contribution of ML systems in your business processes. An ML system is presumably part of the business process because it is making a substantial contribution. It needs to be recognized that the specter of drift comes along with this contribution, and top-level business monitoring metrics need to provide enough visibility to point to drift when it is potentially a factor.
A second approach to output validation operates directly at the ML system’s output. This is a quality control procedure that periodically compares ML system output to human annotation. From their work in developing training data sets, your annotation team will already be familiar with the media associated with your ML system and the desired outputs. As shown in Figure 7, operational ML system outputs are sampled and reviewed by annotators, who assess ML system output by comparing it to their own annotations.
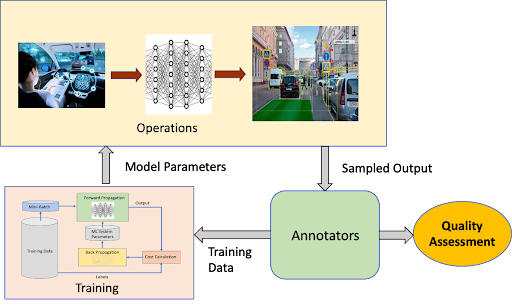
Figure 7. Annotation team detecting drift
The third approach to output validation operates at a lower, technical level. This approach is to detect drift by training a ‘watchdog’ ML system to ‘second guess’ the primary system. Such a system is trained with the same data as the primary system but uses a different architecture and/or parameters.
One approach to developing a watchdog system is to simply retrain the primary system using a different set of initial weights or modified hyperparameters. Another approach is to create a simplified version of the primary system’s architecture by reducing layers, units, or connections. The expectation with these approaches is that even though the primary and watchdog systems will give similar results on the initial training and test data, as drift occurs it will affect the primary and watchdog systems differently. This will create an increase in disagreement that can flag the presence of potential drift and the need for further analysis.
A somewhat different approach is to develop a simple system that does not attempt to make the same fine-grained decisions made by the primary system, but instead recognizes broad categories of situations. For example, a watchdog system for a self-driving car could be trained to classify situations as either dangerous or safe. This could alert the primary system to a danger it might not recognize because of drift affecting the details of a driving scene.
System Monitoring Approaches
Output validation detects drift by comparing system outputs to an alternative, authoritative source. While this is a good way to catch drift, it suffers from the two drawbacks mentioned above: (1) with this method drift may not detected until the ML system is already making errors having an operational impact, and (2) it may not give insight into whether the drift is primarily data drift or concept drift, so additional analysis will be required to figure out how to mitigate the drift.
An alternative and complementary approach to output validation is system monitoring. In this case, intermediate results within an ML system are monitored to provide early indications of drift before business impact becomes significant. In some cases, it can also provide clues on how to fix the drift, e.g., whether it’s data drift or concept drift.
There are several useful ML system monitoring points, as shown in Figure 8.
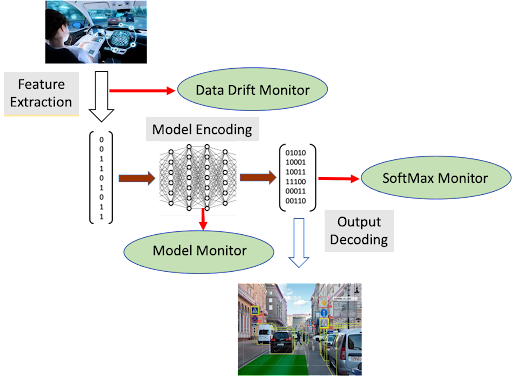
Figure 8. ML System monitoring points
A data drift monitor tracks the statistics of features extracted from the ML system’s operational environment. Baseline empirical distributions of features can be established during training, and these can be compared to distributions calculated during operations. Statistical measures such as the Kolmogorov-Smirnov test (K-S test) can be used for this purpose. Upward trends in the distance between baseline and operational data distributions can be the basis of data drift detection.
A model monitor is an auxiliary ML model (or models) trained to recognize basic patterns that emerge in the baseline operations of the primary ML model. An example would be monitoring the values of normalized outputs of various layers within the model. These values could be input to a neural network trained to distinguish the patterns of normal operation from out-of-range examples included in the training set. This model monitor could then flag potential drift during operation of the primary ML system
Finally, a softmax monitor can give an indication that the ML system is becoming less confident in its decisions, which can be a symptom of drift. A softmax layer is frequently the last stage of an ML system, and it outputs a number for each possible model prediction, the prediction with the largest number being the ML system’s final choice. The softmax numbers are scaled to range from zero to one, with all the choices adding up to 1.0, making them analogous to probabilities for each possible prediction. A high-confidence decision is indicated when the largest softmax value is close to 1.0. When this highest value begins to trend downward, the softmax monitor can flag a possible drift situation.
In summary, system monitoring can detect drift without comparing ML system output to ground truth, which can sometimes be difficult to obtain. System monitoring also has the advantage of potentially detecting drift before it has a large operational impact, and in the case of data drift monitoring, pointing to features and feature extraction as areas to focus on to fix drift.
Mitigating the Effects of Drift
If drift is primarily due to data drift, retraining the ML system with data recently collected from the operational environment may restore performance to operational objectives. This is usually the simplest drift mitigation measure, and it can be tried first and tested to see if it solves the problem. Training impact can be reduced using the techniques of transfer learning, which limits retraining to only portions of earlier versions of the ML system.
As you engage your annotation team in retraining, they can provide insights into potentially significant changes in the input data. They may notice the need for additional input features to distinguish edge cases, or features that should be eliminated because they are no longer useful for making the distinctions the ML system looks for.
If good test results can be obtained by retraining with modified features, then operations can move forward with the newly trained ML system. If sufficient accuracy cannot be obtained through this approach, then changes to the ML system model should be considered. The simplest change would be to increase the compacity of the model, which can generally be accomplished by changing hyperparameters, for example adding additional units or layers. This can generally be accomplished by simply adjusting parameters associated with ML libraries, such as those callable from python, or even more easily in high-level ML development environments.
More radical model changes may be required if increasing model capacity does not yield the desired performance improvement. In this case, a review of models online and in the data science research literature can identify alternatives, such as moving from an LTSM model to a Transformer architecture, or from a multi-layer perceptron to a convolutional neural network.
Concept Drift Detection and Model Retraining Best Practices
Detecting and addressing concept drift requires a systematic approach that combines monitoring, analysis, and strategic intervention. Organizations can implement several proven practices to maintain model performance as operational environments evolve.
Establish Baseline Performance Metrics
Document initial model accuracy, precision, and recall across different data segments. These baselines serve as reference points for detecting performance degradation over time.
Implement Continuous Monitoring Systems
Deploy automated monitoring that tracks both model outputs and feature distributions. Set alert thresholds for significant deviations from baseline performance metrics.
Schedule Regular Model Audits
Conduct periodic reviews of model predictions against human-annotated ground truth data. Expert annotation teams can identify subtle shifts in data patterns that automated systems might miss.
Maintain Version Control for Training Data
Keep detailed records of training datasets, including collection dates, sources, and annotation guidelines. This documentation helps teams understand what has changed when drift occurs.
Develop Rapid Retraining Pipelines
Build infrastructure that supports quick model retraining with new data. Transfer learning techniques can reduce computational costs while maintaining model quality.
Engage Domain Experts Early
Involve subject matter experts when performance metrics begin declining. Their insights can help determine whether drift stems from data changes or more fundamental shifts in the operational environment.
Test Iteratively Before Deployment
Validate retrained models thoroughly before pushing updates to production. Compare performance across historical data segments to ensure improvements generalize appropriately.
Elevate Model Performance with iMerit’s Data Annotation Services
Model drift presents ongoing challenges, but the right partnership transforms these obstacles into opportunities for continuous improvement. iMerit provides software-delivered services for data annotation and model fine-tuning by unifying automation, human domain experts, and analytics into comprehensive solutions.
Our data annotation services combine expert-led labeling with quality control processes specifically designed to address drift. When operational data shifts, our global workforce of domain specialists can rapidly annotate new training datasets that reflect current conditions. This expert-in-the-loop approach ensures annotations maintain consistency with original taxonomies while adapting to evolving edge cases.
Our Ango Hub platform streamlines drift mitigation workflows through integrated monitoring, annotation tooling, and analytics. Teams can track model performance metrics, identify degradation patterns, and trigger retraining pipelines within a single environment. Built-in quality controls and real-time collaboration features help maintain annotation consistency across retraining cycles, reducing the time between drift detection and resolution.
Whether addressing data drift through targeted retraining or managing concept drift with more substantial model updates, our solutions scale to meet production demands. Domain expertise, advanced tooling, and proven methodologies combine to keep ML systems performing optimally as environments change.
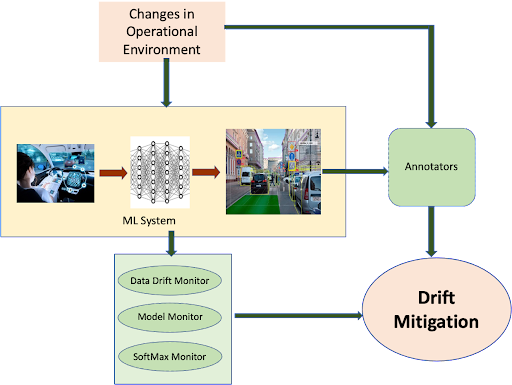
Figure 9. The drift mitigation process
To find out how iMerit can help you keep ahead of machine learning drift, contact our experts today.
References: