Machine Learning: Prior to Model Building
In the world of machine learning, much focus is devoted to the nature of the model. Models are flashy, exciting, and often wow us with their advanced mathematical underpinnings and formal derivations. They are sleek, shiny, and sexy (as much as an algorithm can be), so much so that we often lose sight of why we’re creating the model in the first place.
Models are tools, not ends in themselves. They are only as useful as their ability to generalize to new data. To ascribe higher order virtue to them is to muddy the importance of a machine learning solution’s parts. In fact, much of the success or failure of any given ML use case can be put down to the quality of data sourced and the feature engineering process used.
This article will elucidate some of the steps that must be taken prior to building a model and investigate how they ultimately influence downstream predictions.
Formulating the Problem
Sometimes the most difficult part of an ML application can be formulating the problem itself. It’s important to think critically about what a given problem entails. Is it a supervised, unsupervised, or reinforcement learning task? If supervised, is it a regression or a classification? If unsupervised, is it dimensionality reduction or clustering? Sometimes there is ambiguity, and a problem doesn’t slot neatly into any one given category.
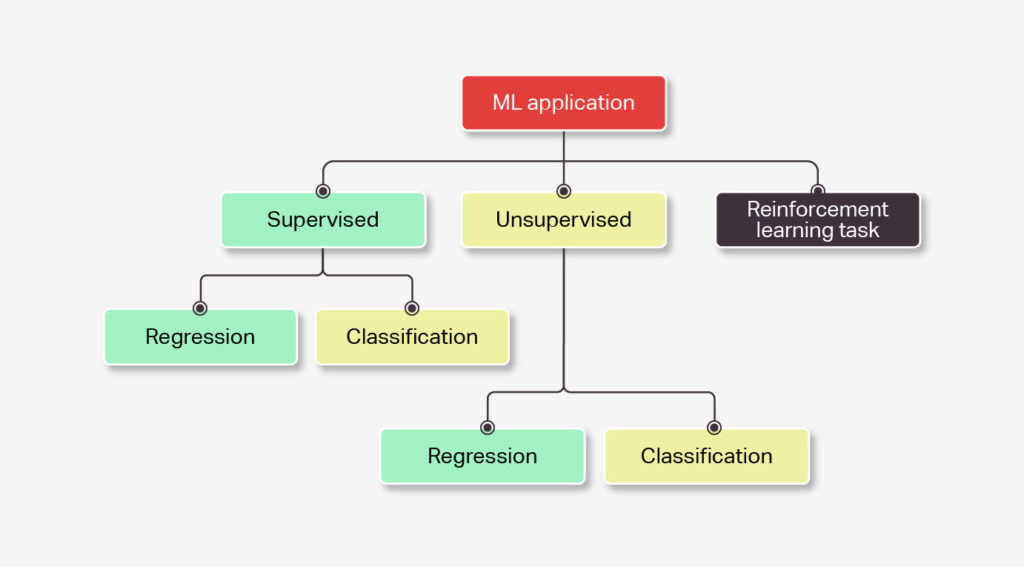
Unlike domains in which solutions are straightforward, ML can be more accurately thought of as a grab bag of techniques, connected loosely by statistical theory. This means that deciding which approach to take for any given problem is not always clear cut.
Surveying the Literature
A deep literature survey can often be the first step towards reducing this ambiguity. Machine learning is a very active field with many new papers published each day, which is both a blessing and a curse. On the one hand, it means that for any given problem or type of data, there is likely a pre-existing approach. Depending on your timeline and goals, you can either adopt this approach directly or use it as a baseline to build off of and test your own method against.
On the other hand, digging through this landslide of information to find what you need can be daunting. Luckily, there are tools that can assist you in this process. Almost all machine learning papers are uploaded to the arxiv, a vast repository of academic papers. There, you can filter by topic and search by authors and paper name.
Another excellent tool is Google Scholar. Each author has their own Google Scholar profile which catalogues all of their academic work. The engine makes it easy to see all this work in one place, which is great for assessing what developments the author has made since publishing the original paper. It’s also simple to navigate to coauthors’ profiles to see what they’ve been working on. Often, this is the first step to finding relevant literature. Another great feature of Google Scholar is that it allows one to explore citation graphs. For any given paper, you can click to see a list of the other papers which have since cited that paper. This is another excellent method for uncovering recent, relevant work.
Finally, within individual papers, there is always a related work list which cites other publications in the field that were used to inform the new method. This is probably the best way to survey literature. Using the citations, it’s possible to trace back through the history of publications all the way to the original, foundational works.
Investigating the Data
Thinking deeply about a problem, the available data, and the end goal are the first steps towards deciding on an approach. Often the data informs the formulation of the problem and the methods to use. There are certain key features to look for in this step of the process.
One is the amount of data available. Smaller datasets require different approaches from larger datasets. Small datasets can often make good use of Bayesian methods whereas large datasets can more effectively employ deep learning. The sparsity of the data is another important consideration. By this is meant the density of nonzero values in the feature vectors, not the size of the dataset. Sparse methods are an entire subset of machine learning and require special considerations for preprocessing of data and computation. They also can often lead to computational speedups.
Another consideration is data structure. Data featurization is not one size fits all. Images and video are often featurized as three-dimensional tensors and fed into convolutional neural networks. Language (text) data is often embedded in a high-dimensional word space and fed into recurrent neural networks such as LSTMs or GRUs. There also exist other types of data that are more naturally structured as graphs. This includes social networks, citation graphs, data about protein-protein interactions, chemical and molecular structures, cross country flight routes, and many more. Such data demands its own class of methods such as graph convolutional neural networks. It also requires unique input representations, most frequently collections of graph adjacency matrices encoding edge relationships between associated node embeddings.
When investigating data, it’s also important to look for any imbalances that might appear. These can be particularly problematic for classification tasks. Certain domains lend themselves to imbalanced classes, i.e. data where the majority of examples are labeled as one of “positive” or “negative”. For example, in rare disease screening you will see far many more examples of healthy people than those with a particular illness. The situation is similar in fraud detection. For a given bank or financial institution, you will (hopefully) encounter far more examples of legitimate transactions than fraudulent ones.
When working with such a dataset, it’s important to rebalance the classes so that the model doesn’t learn skewed relationships. This can be done through techniques such as upsampling the smaller class or downsampling the larger class. There also exist more advanced synthetic data generation methods such as SMOTE which can help alleviate imbalanced class issues. Ultimately, this is a nuanced issue which can be addressed in many different ways.
Putting it All Together
While model building is no doubt an important aspect of machine learning, the tasks which come prior to model creation are just as important, if not more. What all these prior tasks boil down to is proper contextualization. It is vital to understand any given machine learning problem holistically, by taking a deep dive into the surrounding literature and the problems which came before it. The dataset must also be cleaned, processed, and fully integrated into the model building process. Without a proper appreciation for the nuances of any given data, it is impossible to build an effective, generalizable model.
But there are more pieces to the seemingly infinite machine learning puzzle. Models can perform poorly for myriads of reasons, and even the above best practices will not guarantee a high-functioning model. If you’ve done your due diligence and performed each of the above considerations, consider speaking with an iMerit expert today to understand more about where the problem may lie.