Stop training on incomplete datasets. Accelerate AI development with enterprise-grade synthetic data—multimodal, compliant, and built to solve real-world edge cases.
Your Incomplete Dataset Is Affecting Your Model'S PERFORMANCE
Finding datasets that prepare your model to be production-ready is difficult. Not only is real-world data costly to collect, but it often lacks the specific areas and edge cases you need to train on.
Data Scarcity
When you don’t have enough data for rare traffic conditions, or unique medical anomalies for example, models simply fail to perform at production levels.
Data Bias
Models trained on skewed or unrepresentative data can amplify existing biases, leading to unfair and inaccurate decisions.
Privacy & Compliance Risk
Handling sensitive information, such as financial or health data, brings significant legal and security risks to your organization.
BREAKTHROUGH
iMERIT'S SYNTHETIC DATA PLATFORM CAN ENHANCE YOUR TRAINING DATA TO DEPLOY A BETTER MODEL TODAY
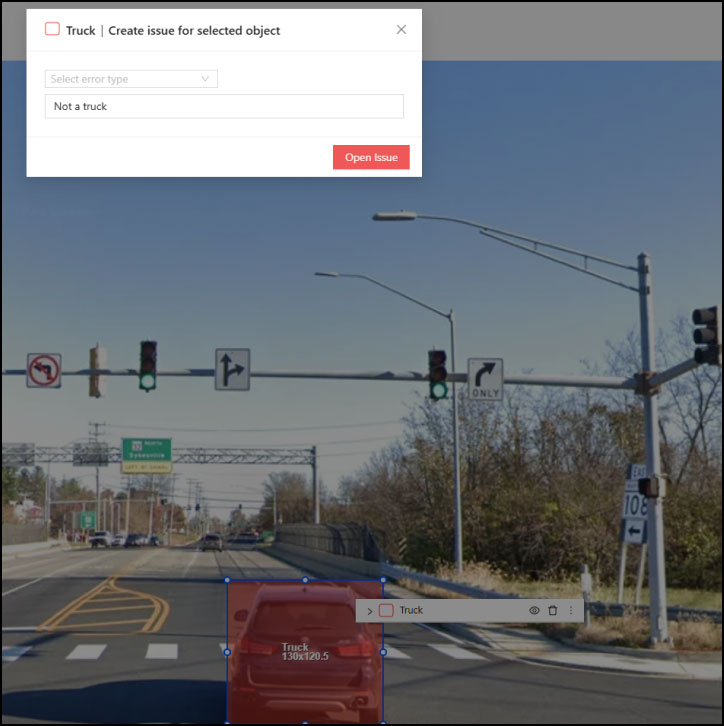
As a part of the annotation process, some of the data will either be outliers or under represented conditions. When Specialists flag these within the UI it can automatically create a new synthetic data project to correct.
ON THE FLY EDGE CASE REPAIR With synthetic data
Using issues flagged by expert annotators during the labeling process as a starting point, we can quickly generate highly specific, targeted data that directly addresses your model’s most critical areas of repair.
SUPPLEMENT YOUR DATASETS with synthetic data
Create an entire dataset of synthetic data instantly to help train against known biases and weak areas of focus. This can be added to existing datasets, or worked on as a new project entirely by our human team of specialists ensuring the highest quality annotations are returned.
TEST A LARGE VARIETY OF LICENSED AND CUSTOM GENERATIVE AI MODELS
We support several of the most common and effective models to build a truly multi-modal capable platform. Or bring your own! We have you covered in a unique prompt testing environment that features all of the tweaks you may want to make.
iMERIT’S SYNTHETIC DATA PLATFORM
MANAGE YOUR SYNTHETIC DATA PROJECTS
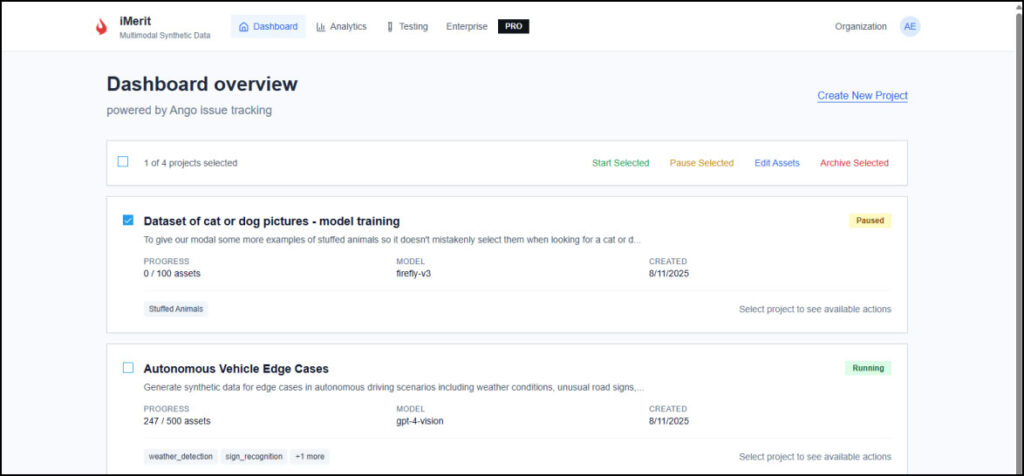
Project Dashboard
View the live status of all your projects, including those running, paused, and completed, across every organization.
Easily filter and search for specific projects to quickly find the information you need.
See progress, the number of assets, and the model used as well as several key data metrics.
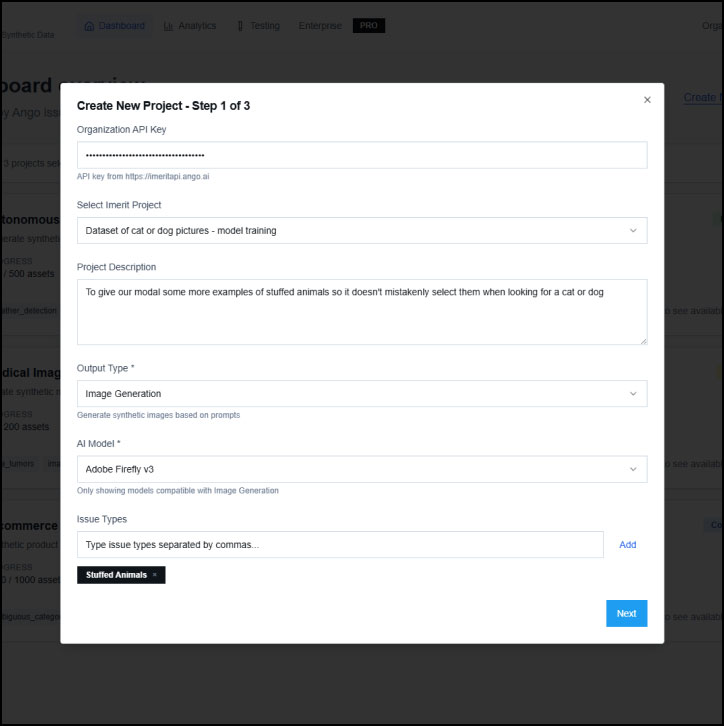
Model Configuration
Adjust key parameters such as the number of assets to generate and the model temperature to control the randomness and creativity of output.
Decide between prioritizing speed or quality to optimize your dataset generation for your specific use case.
Configuration options adapt based on your chosen model and output.
Project Analytics
Gain a holistic understanding of your synthetic data projects with a centralized analytics dashboard.
Monitor essential project data like monthly spend, number of assets generated, and average quality scores.
Visualize monthly trends and usage distribution to understand how your models are performing over time.
Data Lineage Tracking
Easily track the complete lineage of every synthetic data asset from generation to processing.
Verify your data against regulatory certifications like HIPPA and GDPR, with automated checks and audit logs.
Access detailed reports and audit trails for every asset, providing a complete history for governance and quality assurance.
Advanced Multimodal Capabilities
Create complex, synchronized datasets that combine various data types like images, video, Lidar, audio, and text.
Utilize cross-modal correlation to generate realistic relationships between different data modalities.
YOUR MODEL COULD BE LEGIT — BUT REGULATORS DON’T THINK SO
Governance frameworks (labels, audit trails, transparency logs) are now evolving to include synthetic data explicitly. Transparency is no longer optional—it’s what earns trust and keeps regulators satisfied.
KEY BENEFITS
Faster Experimentation Cycles: Rapidly test multiple model hypotheses in parallel, without waiting for costly data collection — accelerating experimentation by 3–5x compared to traditional workflows.
Unlock the Impossible: Create synthetic datasets for rare, dangerous, or impossible-to-capture scenarios — enabling models to cover 90% of critical edge cases that real-world data can’t provide.
Continuous Model Hardening: Continuously stress-test and fortify your models with evolving synthetic scenarios, reducing production failures by up to 40% before they ever hit customers.
3-5x
accelerated experimentation
up to90%
coverage of edge cases
40%
Less production errors
Powering AI Innovation Across Industries
AUTONOMOUS
VEHICLES
Generate synthetic video, Lidar, and sensor data to train models on rare traffic conditions, edge cases, and system malfunctions, improving real-world performance and safety.
FINANCIAL
SERVICES
Create privacy-compliant datasets to train fraud detection models on a wider variety of edge cases, without using real customer information.
RETAIL AND E-COMMERCE
Simulate unique customer behaviors, inventory situations, and operational edge cases to improve forecasting, personalization, and supply chain management.
MEDICAL &
HEALTHCARE
Protect patient privacy while accelerating research by generating synthetic patient data, including rare conditions and clinical edge cases, for testing new medical algorithms and systems.
Frequently Asked Questions
What is synthetic data?
Synthetic data is artificially generated data that mimics real-word data, used to train and test AI models while protecting privacy.
How can synthetic data improve models?
It helps address data scarcity, bias, and edge cases, improving model robustness and compliance.
Is the iMerit Synthetic Data Platform secure?
Yes, it’s designed with compliance-first principles and human-in-the-loop verification.
Ready to
learn more?
Stop waiting for data. Start creating it for better AI today with iMerit.